

…и что она нам дала
Максимальная производительность решений Dorado V6 примерно втрое превосходит показатели систем предыдущего поколения (того же класса) и может достигать 20 млн IOPS.
Это связано с тем, что в прошлом поколении устройств поддержка NVMe распространялась только на пристяжные полки с накопителями. Теперь же она присутствует на всех этапах, от хоста до SSD. Сеть бэкенда также претерпела изменения: SAS/PCIe уступили место RoCEv2 с пропускной способностью 100 Гбит/с.
Поменялся и сам форм-фактор SSD. Если раньше на полку 2U приходилось 25 накопителей, то теперь она доведена до 36 дисков физического формата palm-sized. Кроме того, полки «поумнели». В каждой из них теперь имеется отказоустойчивая система из двух контроллеров на базе чипов ARM, аналогичных тем, которые установлены в центральных контроллерах.
Пока они занимаются только реорганизацией данных, но с выходом новых прошивок к ней добавятся компрессия и erasure coding, что позволит снизить нагрузку на основные контроллеры с 15 до 5%. Перенос части задач на полку заодно высвобождает и пропускную способность внутренней сети. И всё это существенно увеличивает потенциал масштабируемости системы.
Компрессия и дедупликация в СХД предыдущего поколения выполнялась с блоками фиксированной длины. Теперь же добавился режим работы с блоками переменной длины, который пока требуется включать принудительно. Последующие прошивки, возможно, изменят это обстоятельство.
Также коротко о толерантности к отказам. Dorado V3 сохраняла работоспособность, если отказывал один контроллер из двух. Dorado V6 обеспечит доступность данных даже в том случае, если из строя последовательно выйдут семь контроллеров из восьми или одновременно четыре из состава одного «движка».
Что интересного на уровне модуля
Конструкционно все современные СХД от любого производителя выглядят одинаково: во фронтальную часть стального коробчатого шасси устанавливаются контроллеры, в тыльную — интерфейсные модули. Есть еще блоки питания и вентиляции. Казалось бы, все привычно и стандартно. Но на самом деле мы внедрили в эту парадигму много всего интересного.
Начнем с монтажа элементов системы хранения в шасси. Магнитных 3,5-дюймовых дисков в СХД становится меньше, начинают преобладать гибридные системы и all-flash. Но даже несколько дисковых накопителей с частотой вращения шпинделя до 15 тысяч оборотов в минуту создают вибрацию, которую нельзя не учитывать.
Пусть даже на какие-то доли процентов, но на надежность это влияет. А в масштабе крупного ЦОДа доли процентов на один накопитель превращаются в ощутимые показатели отказов и сбоев. Чтобы вибрация отдельных дисков в меньшей степени передавалась через жесткую конструкцию шасси, салазки под диски мы оборудуем резиновыми или металлическими демпферами.
Для шпиндельных накопителей минимальная тряска — уже проблема: головки начинают сбиваться, производительность существенно падает. SSD – другое дело, вибрации они не боятся. Но надежная фиксация компонентов по-прежнему важна. Взять процесс доставки: ящик могут уронить или небрежно швырнуть, поставить боком или вверх тормашками.
Когда-то давно мы начинали с разработки вычислительной техники для телеком-индустрии, где стандарты работоспособности по температуре и влажности традиционно высоки. И мы перенесли их и на другие направления: металлические детали СХД не окисляются даже при повышенной влажности – за счет применения никелирования и оцинковки.
Тепловой дизайн наших СХД разрабатывался с упором на равномерность распределения температуры по шасси – чтобы не допустить ни перегрева, ни слишком сильного охлаждения какого-либо угла дисковой полки. Иначе не избежать физической деформации – пусть даже незначительной, но все-таки нарушающей геометрию и способной привести к сокращению срока работы оборудования. Таким образом выигрываются какие-то доли процента, но на общую надежность системы это все-таки влияет.
Что нового в dorado v6
Линейка продуктов Dorado V6, в частности, представлена системами начального уровня серии 3000. Исходно снабжённые двумя контроллерами, они могут быть горизонтально расширены до 16 контроллеров, 1200 дисков и 192 Гбайт кэша. Также система будет оснащаться внешними портами Fibre Channel (8 / 16 / 32 Гбит/с) и Ethernet (1 / 10 / 25 / 40 / 100 Гбит/с).
Отметим, сейчас сворачивается использование протоколов, не имеющих коммерческой успешности, поэтому на старте мы решили отказаться от поддержки Fibre Channel over Ethernet (FCoE) и Infiniband (IB). Они будут добавлены в более поздних версиях прошивки.
Поддержка NVMe over Fabric (NVMe-oF) доступна «из коробки» поверх Fibre Channel. В следующей прошивке, выпуск которой запланирован на июнь, запланирована поддержка режима NVMe over Ethernet. На наш взгляд, вышеперечисленный набор с лихвой покроет потребности большинства клиентов Huawei.
Файловый доступ в текущей версии прошивки отсутствует и появится в одном из следующих апдейтов ближе к концу года. Реализация предполагается на нативном уровне, самими контроллерами с портами Ethernet, без применения дополнительного оборудования.
Основное отличие модели Dorado V6 серии 3000 от более старших в том, что на бэкенде она поддерживает один протокол — SAS 3.0. Соответственно, и накопители там могут использоваться только с названным интерфейсом. С нашей точки зрения, обеспечиваемой при этом производительности вполне достаточно для устройства такого типа.
Системы Dorado серий V6 5000 и 6000 относятся к решениям среднего класса. Они также выполнены в форм-факторе 2U и оснащены двумя контроллерами. Друг от друга они отличаются производительностью, количеством процессоров, максимальным числом дисков и объёмом кэша. Вместе с тем в архитектурном и инженерном плане Dorado V6 5000 и 6000 идентичны и выглядят одинаково.
К классу hi-end относятся системы Dorado V6 серий 8000 и 18000. Выполненные в типоразмере 4U, они по умолчанию имеют раздельную архитектуру, в которой контроллеры и накопители разнесены порознь. В минимальной комплектации они также могут комплектоваться всего двумя контроллерами, хотя заказчики, как правило, просят установить четыре и больше.
Dorado V6 8000 горизонтально масштабируется до 16 контроллеров, а Dorado V6 18000 — до 32. В этих системах установлены разные процессоры с разным количеством ядер и объёмом кэша. Идентичность инженерных решений при всём при том сохраняется, как и в моделях класса mid-end.
Полки 2U с накопителями подключаются посредством RDMA с пропускной способностью 100 Гбит/с. Бэкенд Dorado V6 старших серий также поддерживает SAS 3.0, но скорее на случай, если SSD-накопители с таким интерфейсом сильно упадут в цене. Тогда возникнет экономическая целесообразность их использования даже с учётом более низкой производительности.
Hypercdp
Если HyperSnap — механизм достаточно традиционный, то HyperCDP — развитие Snapshot с возможностью создания снимков один за другим с большой частотой. Проще говоря, это набор мгновенных снимков, который можно создавать по расписанию с задержкой минимум 3 секунды.
Важно отметить, что подключение получившегося объекта напрямую к заведенным хостам невозможно — из получившегося объекта необходимо сначала сделать копию. Из-за отсутствия записи и прямого чтения снимки HyperCDP могут быть использованы как инструмент для длительного хранения информации.
Помимо функции защиты, HyperCDP имеет еще одно важное преимущество. При использовании данной функции практически не страдает производительность. Это мы и проверим в процессе тестирования.
Для теста заведем на нашей СХД 16 LUN по 512 Гб, подключим их к одной ВМ и дадим нагрузку с помощью бенчмарка VDBench.
Примечание. VDBench сам по себе довольно прост, Oracle распространяет его бесплатно, из сопутствующего ПО требуется лишь установленный JRE.
В вызываемом файле конфигурации необходимо задать параметры, которые будут использоваться при тестировании. Допустим, VDBench будет писать блоком 8 килобайт с 70% полностью рандомного чтения и параметрами дедупликации и компрессии 2 к 1.
На СХД мы также настроим HyperCDP-план, который позволит в процессе делать снимки каждого из 16 LUN’ов с интервалом в 10 секунд. Ограничим эту задачу 500 объектами (для каждого LUN’а). Максимальное же количество в рамках одного плана может быть 60000.

Рисунок 5. Веб-интерфейс с примером созданного HyperCDP-плана.
Остается запустить VDBench с указанными ранее параметрами и наблюдать за текущей производительностью.
В начале эксперимента на тестовой ВМ изменений нет, показания IOPS находятся на том же уровне, учитывая небольшую погрешность измерений.

Рисунок 6. Результаты теста HyperCDP.
Подождем еще немного, пока количество HyperCDP-объектов всех LUN’ов не перевалит за сотню, и проверим еще раз.

Рисунок 7. Результаты теста HyperCDP с количеством объектов более 100.
Подводя промежуточные итоги, стоит отметить, что эмулируемый в рамках теста сервис не испытал каких-либо воздействий в плане деградации производительности, и за полтора часа мы получили 500 снимков 16-ти LUN’ов, что в сумме составляет 8000 объектов.
На мой взгляд, эта функция может быть востребована при работе с активно используемыми и загруженными базами данных, где за секунды число транзакций значительно возрастает и возможность отката на десяток секунд вполне пригодится.
Hypersnap
HyperSnap представляет собой ни что иное, как Snapshot, созданный на LUN’е. Используется для резервного копирования, тестирования и других задач.
Важно отметить, что такой Snapshot работает по принципу ROW (redirect-on-write), вместо ранее считавшимся классическим COW (copy-on-write). Согласно этому алгоритму, новые данные не заменяют на старые, а записываются на свободное место. Такой Snapshot по сути является таблицей со ссылками.
Собственно, алгоритм ROW — уже своего рода классика для Flash-массивов.

Рисунок 2. Отличия алгоритмов COW и ROW.
Примечание. Известные системы резервного копирования, например, от Veeam и Commvault, поддерживают интеграцию с инструментами Huawei и могут использовать Snapshot для резервного копирования, расширяя таким образом «окно бэкапа» (оптимальное время, подходящее для создания копий, когда нагрузка на систему минимальна).
Технология HyperSnap позволяет подключать созданный снимок к серверу подобно обычным логическим дискам LUN. Их можно монтировать не только на чтение, но и на чтение-запись для оперативного подключения актуальных данных к тестовой среде.
На рисунке 3 показан снимок, созданный с именем LUNGroup006_last, прародителем которого является диск LUN — LUNGroup006_000. LUNGroup006_000 при этом уже был смонтирован на одной из тестовых виртуальных машин.

Рисунок 3. Мгновенный снимок HyperSnap с именем LUNGroup006.
Подключаем его на тот же хост и следим через интерфейс фирменного драйвера MultiPath от Huawei — UltraPath. Эта функция является не только важным элементом отказоустойчивости, но и просто удобным рабочим инструментом, способным прямо с хоста однозначно определить доступные тома.

Рисунок 4. Консоль управления фирменного драйвера MultiPath от Huawei — UltraPath.
В итоге мы вполне можем снять Snapshot сервиса, находящегося в Production, и смонтировать его в тестовой среде для проверки обновлений, новых решений и прочих задач, никак не затрагивая рабочую систему или сервис.
Кроме того, LUN’ы можно добавлять в так называемые Consistency Groups, что позволяет делать снимки указанных данных в один и тот же момент данных. Это крайне важно, если вы придерживаетесь рекомендаций вендоров и раскладываете файлы и логи тех же баз данных по разным LUN’ам.
Smartqos
В принципе, сервис SmartQoS — штука не новая. Системы, которые обеспечивают нужную полосу пропускания для критичных сервисов за счет приоритизации, существовали и ранее. Использовать разные LUN’ы под различные сервисы — совершенно нормальная практика.

Рисунок 10. Настройка политики SmartQoS.
Такой подход бывает необходим в определенных ситуациях, например, утренний Boot Storm у VDI. Инженеры Huawei учли этот факт — есть возможность включать нужный режим QoS по расписанию.
Функция «прячется» под кнопкой Advanced.
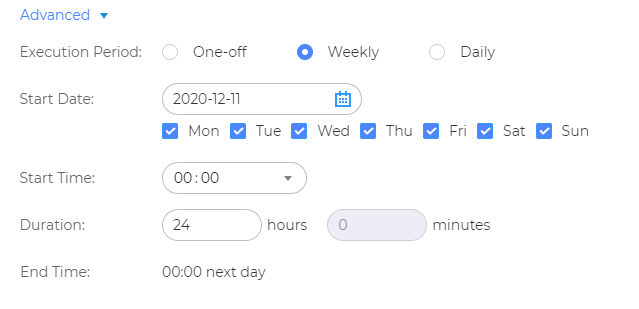
Рисунок 11. Настройка расписания (раздел Advanced).
Выполнить проверку просто — необходимо создать политику SmartQOS для одного из LUN’ов с параметрами ниже.

Рисунок 12. Созданная политика SmartQoS001.
Далее снова обратимся к помощи бенчмарка VDBench (в тестировании он встретится еще не раз). СХД с точностью как в аптеке отмеряет нашей эмуляции сервиса предоставляемые IOPS’ы. Для наглядности ниже привожу показания со стороны тестового ПО и со стороны Dorado.
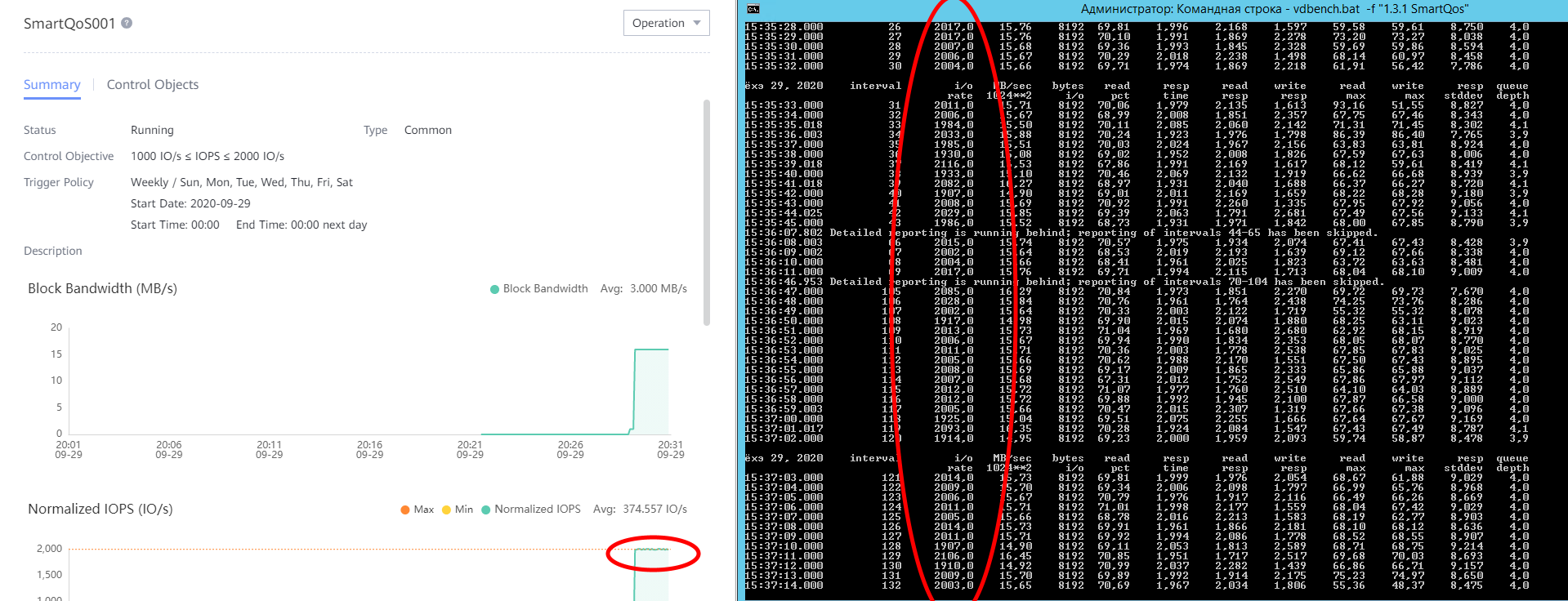
Рисунок 13. Результат выполнения политики SmartQOS.
Выглядит SmartQOS весьма неплохо. По результатам его тестирования могу порекомендовать Dorado к использованию в любой инфраструктуре как для оптимизации работы уже существующих сервисов, так и для изначального планирования, особенно если в СХД размещены крупные базы данных или VDI, требующие «особого подхода».
Для последних также важно наличие такой настройки как Burst, когда политика позволяет превысить максимальные значения на определенный срок, задаваемый администратором. Это поможет проще пережить уже упоминаемый ранее Boot Storm. Если у Dorado будет возможность не жертвовать другими сервисами, она спокойно перейдет в режим Burst в политике и обеспечит требуемые параметры производительности.
Внутри контроллера
Контроллеры Dorado V6 выполнены на нашей собственной элементной базе. Никаких процессоров от Intel, никаких ASICs от Broadcom. Таким образом, все до единого компоненты материнской платы, равно как и она сама, полностью выведены из-под влияния рисков, связанных с санкционным давлением со стороны американских компаний.
Те, кто своими глазами видел любое наше оборудование, наверняка замечали шилды с красной полосой под логотипом. Она означает, что в изделии отсутствуют американские компоненты. Таков официальный курс Huawei — переход на компоненты собственного производства или, во всяком случае, выпускаемые в странах, не следующих в русле политики США.
Вот что можно увидеть на самой контроллерной плате.
- Универсальный сетевой интерфейс (чип Hisilicon 1822), отвечающий за подключение к Fibre Channel или Ethernet.
- Обеспечивающий удаленную доступность системы BMC-чип, а именно Hisilicon 1710, для полнофункционального дистанционного управления и мониторинга системы. Подобные применяются также в наших серверах и в других решениях.
- Центральный процессор, в качестве которого выступает построенный на архитектуре ARM чип Kunpeng 920 производства Huawei. Именно он показан на схеме выше, хотя в других контроллерах могут быть установлены отличные от него модели с иным числом ядер, другой тактовой частотой и т. д. От модели к модели меняется и количество процессоров в одном контроллере. Например, в старших сериях Dorado V6 на одной плате их четыре.
- Контроллер SSD (чип Hisilicon 1812e), который поддерживает подключение как SAS-, так и NVMe-накопителей. Добавим, Huawei самостоятельно выпускает SSD, однако не изготавливает сами ячейки NAND, предпочитая закупать их у четырёх крупнейших мировых производителей в виде неразрезанных кремниевых пластин. Распил, тестирование и упаковку в чипы Huawei производит самостоятельно, после чего выпускает их под собственной торговой маркой.
- Чип искусственного интеллекта — Ascend 310. По умолчанию на контроллере он отсутствует и монтируется через отдельную карту, которая занимает один из слотов, отведённых под сетевые адаптеры. Чип применяется для обеспечения интеллектуального поведения кэша, управления производительностью или процессами дедупликации и компрессии. Все эти задачи могут быть решены и силами центрального процессора, но чип ИИ позволяет делать это намного эффективнее.

Лайфхак номер два: hedexlite!
Итак, вы нашли нужный вам документ, но это ещё не все приятности!
Обратите внимание — при открытии соответствующей библиотеки в режиме онлайн-просмотра вверху страницы отображаются ссылки для скачивания данной библиотеки, а также программы «HedexLite» для её просмотра:
В этой документации собрано огромное количество удобно скомпонованной по разделам информации, которая снабжена перекрёстными ссылками для простоты использования:
- Список новых функций в текущей версии с описанием возможностей.
- Описание линейки, позиционирование моделей, типовые сценарии использования и прочее.
- Описание аппаратной платформы, включающее:
- внешний вид каждой модели маршрутизатора, с описанием всех компонентов (встроенные порты, слоты для плат и блоков питания, индикаторы, болты заземления и т.д.);
- правила нумерации слотов;
- схема обдува;
- технические характеристики (процессор, память, размер, вес, энергопотребление, рабочий диапазон температур и т.д.);
- аналогичное описание на все платы, кабели (с распиновкой, если необходимо), трансиверы (с оптическими бюджетами), блоки питания и вентиляторов.
- Инструкция по монтажу.
- Подробная инструкция по настройке, разбитая на секции (в рамках каждой секции — набор типовых разделов конфигурации с описанием шагов и ссылками на встроенный же «command reference», где описаны все возможные параметры команд).
В конце каждого раздела присутствует сборник типовых примеров конфигурации, где представлен набор типовых топологий с примером интерфейсов. Также дается инструкция по настройке всех устройств на топологии с учетом интерфейсов и IP-адресов, команд для промежуточной проверки правильности настройки и получившиеся фрагменты конфигурационного файла.
- Раздел «Operation and Maintenance» с описанием эксплуатационных регламентов (если требуются) и типовыми опросниками с командами для проверки состояния устройств.
- Раздел с описанием возможных аварий и порядком действий, которые необходимо выполнить при возникновении инцидентов, а также сборник инструкций по диагностике и решению типовых неисправностей (например, инструкция по сбросу пароля на консоль, если он по какой-либо причине был утерян).
- Уже упомянутый «command reference» с подробным описанием всех возможных параметров команд конфигурации и диагностики.
Скачав HedexLite, вы получаете ряд дополнительных полезных функций, таких как:
- загрузка документации с портала поддержки;
- проверка наличия обновления документов в библиотеке, а также проверку наличия уже неактуальных версий документов (которые можно удалить);
- гибкая система поиска по документации, с возможностью фильтрации результатов поиска по разделам; например, выполнив поиск по ключевому сообщению «ospf», можно отфильтровать результаты по типу документа:
Лайфхак номер один: читайте документацию!
Да-да, именно так! Ответы на большую часть задаваемых вопросов можно без особых трудозатрат почерпнуть из доступных на портале компании документов.
Вы можете возразить, мол «бытует мнение, что какой-либо стоящей документации на оборудование Huawei в публичном доступе не существует — и вообще, есть сомнения, что таковая существует в природе».
Отвечаем — это миф. Безусловно, он возник не на пустом месте, и несколько лет назад, когда было создано подразделение Huawei Enterprise, большая часть материалов и документации действительно носила гриф «Internal», а портал компании был не богат общедоступными материалами.
Безусловно, большой объем документации таит в себе и другую проблему для специалистов — проблему трудоёмкого поиска нужной информации для решения своих задач. Зачастую специалисты боятся «утонуть» в море инструкций, документов и спецификаций. Данная проблема актуальна как для проектировщика, занимающегося выбором моделей оборудования и планированием его размещения в стойках, так и для системного администратора или специалиста эксплуатации, занимающегося настройкой сети и пытающегося разобраться — почему индикатор на плате мигает зелёным цветом дважды в секунду.
Мы постарались решить и эту проблему. На «территории Huawei» вы можете смело забыть об «информационных раскопках» — здесь вам понадобится всего один документ, выпускаемый на линейку оборудования для конкретной версии ПО. Доступность же новых версий отслеживается автоматически, для этого вам достаточно лишь иметь аккаунт на нашем сайте поддержки.
Для примера, взгляните на документ на серию маршрутизаторов AR G3 версии V200R008 — «Huawei AR120&AR150&AR160&AR200&AR500&AR510&AR1200&AR2200&AR3200&AR3600 Product Documentation».
Найти такие документы труда не составит — выберите в разделе поддержки интересующий продукт и примените фильтр по категории «Product Documentation»:
Секунда на аварийное переключение
В Solution A на иллюстрации выше можно узнать нашу систему предыдущего поколения Dorado V3. Четыре её контроллера работают попарно, а копии кэша содержатся только в двух контроллерах. Контроллеры внутри пары могут перераспределять нагрузку. В то же время, как видите, здесь нет «фабрик» фронтенда и бэкенда, так что каждая из полок с накопителями подключается к конкретной контроллерной паре.
На схеме Solution В показано присутствующее сейчас на рынке решение от другого вендора (узнали?). Здесь уже есть и фронтенд-, и бэкенд-фабрики, а накопители подключаются сразу к четырём контроллерам. Правда, в работе внутренних алгоритмов системы есть не очевидные в первом приближении нюансы.
Справа представлена наша текущая архитектура СХД Dorado V6 со всем набором внутренних элементов. Рассмотрим, как эти системы переживают типичную ситуацию — выход одного контроллера из строя.
В классических системах, к числу которых относится и Dorado V3, период, требующийся на перераспределение нагрузки при отказе, достигает четырёх секунд. На это время ввод-вывод полностью останавливается. В решении Solution В от наших коллег, несмотря на более современную архитектуру, время простоя при отказе даже выше — шесть секунд.
СХД Dorado V6 восстанавливает свою работу всего через одну секунду после отказа. Такой результат достигается благодаря однородной внутренней RDMA-среде, позволяющей контроллеру обращаться к «чужой» памяти. Второе важное обстоятельство — наличие фронтенд-фабрики, благодаря которой путь для хоста не меняется. Порт остаётся прежним, а нагрузка просто отправляется на исправные контроллеры драйверами мультипассинга (multipassing).
Выход из строя второго контроллера в Dorado V6 отрабатывается за одну секунду по той же схеме. У Dorado V3 это занимает около шесть секунд, а у решения другого вендора — девять. Для многих СУБД подобные интервалы уже нельзя считать приемлемыми, так как за это время система переводится в режим standby и перестаёт работать. Это перво-наперво касается СУБД, состоящих из множества разделов.
Выход из строя третьего контроллера Solution A пережить не в состоянии. Просто в силу того, что пропадает доступ к части дисков с данными. В свою очередь, Solution В в такой ситуации восстанавливает работоспособность, на что требуется, как и в предыдущем случае, девять секунд.
Что у Dorado V6? Одна секунда.
Технологии
Тут описаны технологии, которые не рассмотрены в RAID-контроллерах
Cache mirroring
Cache mirroring используется при наличии нескольких контроллеров в СХД (у Huawei всегда несколько контроллеров, минимум 2). Данные между контроллерами по шине синхронизации синхронизируются для целостности данных в случае отказа одного из контроллеров. Cache mirroring делается всех типов операций – read/write/mirror. Причем главным считается write.
Multipathing
Multipathing – поддержка нескольких аплинк каналов от СХД до серверов. Нет зависимости от канала/промежуточного коммутатора. Особенность технологии еще и в том , что можно сделать так, чтобы для сервера оба канала виделись как один ЖД (LUN), а не по одному LUN на каждый канал.
Data coffer
На случай полного фатала с питанием (выход из строя двух БП/обоих лучей питания) в controller enclosure встроен функционал сохранения данных RAID кэша. Реализуется не через BBU ОЗУ или суперконденсаторы flash, как на RAID-контроллерах серверов (и на старших моделях СХД), а используя батареи (батарейные блоки BBU) служебное пространство 4 дисков.
При проблеме с питанием данные из кеша контроллера переносятся на специальные разделы coffer disk’ов (раздел равен кешу контроллера, 4 диска – 2х2 диска в RAID1). Остальная часть дисков, не отведенная под раздел coffer, используется стандартно. После включения контроллер выгружает данные из coffer куда нужно.
LUN copy
Копирование LUN. Требует запрет на запись (не на чтение) в данный LUN для корректного снятия копии в определенный момент времени.
HyperClone (LUN clone) и Synchronization
Мгновенное копирование LUN используя синхронизацию (synchronization) между LUN. Не требует запрета на чтение, но занимает весь объем, отведенный под LUN, а не только объем данных LUN.
Синхронизация может происходить как между основным и резервным LUN, так и обратно. Для восстановление данных используется обратная синхронизация с клонированного LUN на основной (reverse synchronization). После синхронизации происходит обрыв синхронизации (split)
HyperSnap (Snapshot)
Позволяет снять копию системы (определенного LUN) в определенный момент времени. Есть у всех вендоров СХД. У Huawei основан на технологии copy-on-write (еще популярен у вендоров allocated-on-write).
- Для снятия snapshot не требуется остановка системы, в отличии от LUN copy.
- Snapshot занимает только пространство отведенное под ненулевые данные LUN, а не весь объем, отведенный под LUN, как это делает Clone.
В СХД типа OceanStor 9000 snapshot может быть сделан за одну секунду без влияния на сервис. Подробнее зачем нужны snapshot/replication см. в статье backup.
Существует два варианта восстановления из snapshot:
- side-by-side recovery: создается сопоставление snapshot LUN для хоста, который “видит” оригинальный LUN. В результате конкретные данные могут быть скопированы на уровне ОС.
- rollback function: оригинальный LUN (и все его данные) просто подменяется snapshot LUN.
HyperReplication (Remote Replication)
Репликация данных с одного СХД на другой. Требует несколько одновременно работающих СХД в отличии от LUN copy/snapshot, которые могут быть сохранены на том же СХД. Репликация может быть синхронная или асинхронная (с задержкой), в зависимости от ширины канала и задержки:
- Синхронная репликация – при записи хоста на основной СХД хост не получит подтверждение успешности записи пока основной СХД не получит подтверждение от СХД, с которым происходит репликация.
- Асинхронная репликация – основной СХД сразу отвечает хосту, а уже на фоне просто делается snapshot и далее данные передаются на второй СХД.
В настройках обычно можно задавать максимальную полосу канала, выделяемую под репликацию. Кроме того реплики могут быть полными или инкрементальными.
Могут быть разные варианты реализации репликации между СХД: один к одному/ко многим или двухсторонние реплики. Подробнее зачем нужны snapshot/replication см. в статье backup.
Квоты
Квоты позволяют сделать ограничение для определенных пользователей по объему выделяемого им пространства. Зачастую поддерживается интеграция с NIS/LDAP/AD (слайд для СХД OceanStor 9000).
WORM
WORM – write once read many. Система блокирует после создания файла его изменение и удаление. Таким образом обеспечивается неизменяемость информации (отчеты сотрудников, правовая или медицинская информация). Через определенный период, заданный админом, файл можно удалить или повторно заблокировать, но изменить нельзя.
QoS
Аналогия QoS в IP-сетях, вместо пакетов используются I/O requests. Можно в системе настраивать приоритетность обработки тех или иных запросов на чтение/запись на определенный LUN. В зависимости от приоритета формируются очереди.
Дедупликация
В СХД может быть реализован функционал глобальной дедупликации данных (защиты от дублирования) путем сравнения файлов или объектов между собой (OceanStor 9000). Подробнее о дедупликации см. в отдельной статье.
HyperThin/SmartThin
Thin LUN – динамический LUN, который автоматически расширяется при заполнении. ОС видит такой LUN как обычный Thick LUN, но по факту контроллер предоставляет меньше объема, чем размер LUN и автоматически расширяет его при потребности ОС.
Пространство без данных можно использовать для другого LUN. В результате пространство используется эффективнее, но в случае полной забивки динамического LUN может произойти коллапс. При создании Thin LUN отжирает 64МБ под свои задачи и по мере появления данных в Thin LUN потребует еще служебного пространства, помимо основных данных.
SmartTier
У вендоров может быть реализована поддержка разных типов дисков (SSD, SAS, NL-SAS). В результате разные по типу диски могут стоять в одной полке. В случае Huawei технология называется SmartTier и поддерживается на RAID 2.0 и СХД OceanStor 9000 (тут она InfoTier). Для работы SmarTier на Disk Domain нужно чтобы в нем были диски разных типов (не обязательно три типа, можно и два).
SmartTier на основе технологии dynamic storage tiering (DST) определяет, какие данные более востребованы и переносит их на SSD (high-perfomance tier), менее же востребованные же переносит на HDD (perfomance tier: SAS, capacity tier: NL-SAS). Происходит это в три этапа:
- Анализ входящих/исходящих операций (i/o monitoring)
- Анализ возможностей размещения данных (data placement analysis)
- Перемещение данных (data relocation)
Перемещение происходит в ненагружанные часы (можно задать вручную или использовать автоматический выбор на основе i/o), потому что потребляет ресурсы СХД . Определенные файлы можно закрепить за каким то уровнем. По умолчанию функционал выключен, даже если лицензия куплена – нужно задавать настройки политик перемещения для определенного LUN (automatic, highest, lowest, no relocation).
Специфические утилиты восстановления
Могут быть реализованы специфические утилиты восстановления данных, например, функционал по восстановлению видео (в OceanStor 9000). Как говорит автор до такого лучше не доводить – лучше следить за состоянием RAID/ЖД в нем, делать snapshot и прочее.
Выводы
Huawei OceanStor 2200 V3 — это пример того, как за относительно малые деньги можно приобрести очень функциональную СХД для SAN-приложений. Пожалуй, самый главный плюс данной модели — это технология RAID 2.0 , благодаря которой можно спать спокойно, когда из RAID 5 массива вылетает один жесткий диск:
через 40 минут массив будет в состоянии Healthy, а если свободное место позволяет, можно неспешно ждать новый диск из гарантийного ремонта, не опасаясь за сохранность данных. Такое отказоустойчивое решение, которое на уровне железа дублирует все компоненты, а на уровне софта решает многолетние проблемы RAID-массивов идеально вписывается в концепцию файлового архива или СХД для разработчиков программного обеспечения.
Поскольку это все же начальный уровень, и цена здесь имеет большое значение, для хранения резервных копий OceanStor 2200 V3 можно использовать даже без хост-адаптеров: восьми гигабитных ETH портов хватит для резервирования по iSCSI целого небольшого офиса.
Конечно, в начальном ценовом сегменте не обойтись без недостатков, и к ним я могу причислить отсутствие горизонтального масштабирования, поддержки файлового доступа в 16-гигабайтной версии и неадекватно дорогую лицензию за репликацию и клонирование LUN-ов, ведь эти функции, как правило, бесплатные даже в более дешевых устройствах.
К счастью, без репликации и клонирования LUN-ов можно обойтись или при необходимости, возложить эти задачи на какой-нибудь виртуальный сервер с установленным Rsync. А на сэкономленные деньги лучше приобрести пакет расширенной гарантии, ведь далеко не каждой системе хранения данных стоимостью в 400 тысяч рублей можно обеспечить официальный сервис с круглосуточным выездом специалиста в ЦОД.
Для многих государственных предприятий расширенная гарантия — это не только личное спокойствие начальника IT-отдела, но и прекрасный способ ограничить предложение аналогов при закупке оборудования на торгах, и видимо компании Huawei это хорошо известно.
Михаил Дегтярёв (aka LIKE OFF)

