
Deep Review Deep Learning Hall-level Overview-Notes
The proliferation of online reviews is a goldmine for customer experience analysis. Our AI solution automates the processing of this data to offer you innovative data-driven solutions that improve your performance.
Functionalities
Deep learning allows a computational model composed of multiple processing layers to learn data features with multiple levels of abstraction. These methods have greatly improved the latest technologies in many other fields such as speech recognition, visual object recognition, object detection, and drug discovery and genomics. Deep learning uses backpropagation algorithms to instruct the machine how to change its internal parameters (used to calculate the features in each layer from the features in the previous layer) to discover complex structures in large data sets. Deep convolutional neural networks have brought breakthroughs in processing images, video, speech and audio, while recurrent neural networks have demonstrated sequential data such as text and speech. (that is, find a complex function accurately through learning, and then use this function in the project to achieve our purpose) Deep Learning has three core elements: a kind of representation learning methods The essence of deep learning is that the features on each layer are not designed by human engineers, but are actively learned from data through a type of general-purpose learning procedure. with multiple levels of representation from raw to abstract Taking pictures as an example, the original data is just a matrix of meaningless pixels. The first layer of features learned by deep learning can detect whether there are lines pointing to a certain direction in the picture; higher-level features are combined with lower-level features at a more abstract level-such as specific patterns- Detection. non-linear transformation of representation In theory, by combining a sufficient number of nonlinear transformations, any function can be fitted. It can be seen that Deep Learning is very good at mining the internal structure of high-dimensional data
The limitation of traditional machine learning algorithms is that they are often difficult to process unprocessed natural data, such as an original RGB image. Therefore, to build a traditional machine learning system, it often requires some experienced engineers to design a feature extractor to convert the original data into a feature representation that can be recognized by the machine.
Application areas of deep learning: (eg: face recognition, black and white image coloring, automatic machine translation, Go, target detection, automatic driving) (1)Computer vision Unmanned driving field: vehicle recognition, path planning Image recognition field: image representation, semantic segmentation (2) Natural language processing Smart search, man-machine dialogue, text summary, machine translation (3) Other aspects Medical image analysis, autonomous driving, pharmaceuticals, face recognition, machine translation, virtual assistants, games, security, anomaly detection, analysis and prediction
Over the past six years, Amber Mark has crafted consistent pop-R&B music with tasteful, glossy precision. The New York artist’s first two EPs, 2017’s 3:33 AM and 2018’s breakthrough Conexão, examined themes of grief and love through lithe R&B, pop, dance, and bossa nova, melding different sounds into one elegant, rhythmic blend. She separated herself from her peers by leaning into stormy, overwhelming emotion, whether swimming through a monsoon of tears on an undulating ballad or demanding equal footing in a relationship over a jubilant house beat.
Mark’s impressive, husky voice suits her genre-hopping music, which hit a stride in 2020 on her quarantine-made covers series that allowed her to stretch her legs and experiment, especially in its more offbeat, cheeky exercises (see: her house-infused, unexpectedly delightful spin on Sisqó’s “Thong Song”). That set serves as a playful aperitif for Three Dimensions Deep, Mark’s polished, long-awaited debut. Moving smoothly between R&B, funk, and pop, the fully realized album foregrounds Mark’s vocals and songwriting, scrutinizing her self-doubt as a way to cast it out and build self-confidence.
The album is structured in three acts mapping Mark’s journey at different stages: identifying her own insecurities, working through the messy parts of self-discovery, and finally reaching a solid sense of self-worth. Three Dimensions Deep’s secondary, figurative throughline is inspired by Mark’s love of sci-fi and interest in heady astrophysics theories, a theme that pops up through celestial metaphors in her lyrics that amplify human concerns to galactic size. In Mark’s world, romance hurtles her to another planet, kisses are astronomical, and searching for her place in the world is posed as an all-consuming, cosmic question.
Mark makes the concept work, using it as a loose framework for plush, tightly produced songs whose subjects range from tossing men in the trash to battling dark nights of the soul. “Trying to see where life leads, where the future lies/Anxiety all of me keeping me up at night,” she admits on “One” over a chopped-up blues sample and knocking beats. The concession feels honest, with Mark taking stock of the uncertainty of her future and emerging freshly determined to take control of it. “On & On” describes another battle with self-doubt over a stomping drumbeat and sumptuous strings, making the mental slump of questioning one’s worth sound refreshingly comforting. She uses the occasional astral image, like looking up into the night sky, to illuminate small junctures of uncertainty and distance.
Mark tempers the album’s vulnerable moments with upbeat songs that traipse through sultry nights out and scenes from her love life. Early highlight “Most Men” unspools slowly, as organ chords give way to a laidback beat at the halfway point and Mark immortalizes the one true commandment when it comes to dating: “Most men are garbage.” Later, she moves on from terrible exes on the seductive “Softly,” which loops the guitar melody from Craig David’s 2000 song “Rendezvous” into a throbbing R&B backdrop for the heated tension she feels with a potential partner. Mark co-produced or engineered over half of the album’s 17 tracks and makes her fingerprints known, shifting easily from velvety, percussive R&B (“Worth It”) to sleek pop-funk (“Darkside”). Small details—a slight key change, stacked murmured vocals, luxuriant extended outros—work like choice accessories on Mark’s signature, memorable style.
As on her previous EPs, Mark’s dynamic voice imbues the album with its most emotive, surprising turns. On the sauntering “What It Is,” she stretches her vowels over cascading, layered vocals and a scorching guitar solo. Later she adopts a conversational flow to indulge in a glitzy lifestyle on “Foreign Things,” and strikes a smoky, melancholy tone during “On & On.” The depth and dexterity make for one of the album’s most engaging qualities; even when Mark reaches for an obvious lyric, as on the arguably outdated chorus of “FOMO” or the neutral-to-a-fault “Competition,” her rich, varied performance transforms the occasional errant choice into an opportunity for another compelling vocal phrasing.
Energetic, lush, and measured, Three Dimensions Deep is a cohesive debut from Mark that doesn’t lose sight of the bespoke sound that she’s developed over the years. Here, Mark’s music accomplishes its goal of making the pursuit of figuring out who you are, what you stand for, and how you can make it through the world feel as immense as a meteor cratering into the moon. But that kind of outsize passion feels exceptionally true to life, especially as rendered in Mark’s capable hands.
Catch up every Saturday with 10 of our best-reviewed albums of the week. Sign up for the 10 to Hear newsletter here.
Using Artificial Intelligence to Enable Patient-Driven Healthcare
In a world driven by social media and online forums, healthcare systems have an opportunity to identify and act on very specific insights directly from patients. Sia Partners has taken important learnings from other industries that have capitalized on customer sentiment analysis and applied the same principles to analyze the sentiments of patients within a healthcare system. The use of patient sentiment analysis to analyze patient opinions can be used to track patients’ unique and specific thoughts and experience about a healthcare service, product, medication, and more.
Tracking and analyzing patient feedback can and should be a crucial input into decision making for healthcare organizations providing necessary insights to drive innovation.
Patient sentiment analysis is a form of text analytics that determines the attitude that patients have towards aspects of a service or product by extracting the sentiment of these patients’ feedback from various online platforms such as Google reviews, Healthgrades, and ZocDoc. Sentiment analysis uses natural language processing (NLP) to score each piece of text in a patient review based on the sentiment of the words and phrases. On a broad scale, sentiment analysis is beneficial because it:
- Can manage large volumes of patient insights data better than humans;
- Reduce reliance on human intuition, which tends to be riddled with biases;
- Can synthesize findings quickly.
What is Natural Language Processing?
NLP is a branch of Artificial Intelligence (AI) that provides computers the ability to understand text and spoken words similar to the way humans can. This technology combines computational linguistics — the foundation for rule-based models of human language — machine learning, and deep learning models.
Current sentiment analysis uses machine learning to determine the meaning behind patient reviews to account for the subtleties in human language. It recognizes the sentiment behind words based on a labelled training set. Continuous innovation has made it possible for sentiment analysis to take into account sentiments based on polarity, emotions, intentions, and urgency.
Heka by Sia Partners’ Sentiment Analysis Tool
Sia’s DeepReview tool leverages Natural Language Processing to analyze patient reviews, metadata, business data, socio-demographic data, and affiliate data to generate indicators that can be applied to networks and geographic areas. Using AI, DeepReview collects comments from various opinion sources; this data often remains untapped as its consolidation is complex and time-consuming. DeepReview drives incredible insight with real time tracking and understanding, communicating the main themes that impact patients’ experience.
Improving Patient Adherence
In order to prevent unnecessary costs and patient readmissions, an investment in patient sentiment analysis can be used to help healthcare providers and hospital systems understand what is driving a lack of patient adherence. This investment will ultimately provide healthcare clinicians with insights to prevent readmissions and reduce avoidable complications.
The costs of not implementing patient sentiment analysis can be high. Healthcare providers can risk poor patient retention, unnecessary readmission costs, and Medicare reductions.
By aggregating reviews and tracking satisfaction and dissatisfaction, healthcare providers, hospitals, and healthcare systems can identify effective processes and changes from ineffective — those lacking adoption or satisfaction with patients. Understanding where pain points exist for patients enables healthcare providers to focus their efforts on value-add; adjusting to meet patient needs and expectations. DeepReview data gives healthcare the power to improve not only patient adherence, but also to improve patient outcomes, and optimize healthcare costs — all while truly giving a voice to those who matter most, the patients.


“Brightly lit tunnel. No possibility of danger here.”
When reviewing indie games, one has to keep in mind that there’s a logistical constraint to them. It’s small teams, sometimes even just a single person, and that can limit what one can do. On the other hand, one person can turn out amazing games. “Notch” did it with Minecraft. Phil Fish did it with Fez. Which makes it all the more aggravating when a one-man band turns out a game that fails to entertain. Hidden Deep falls squarely into that category.
Notionally inspired by horror classics as The Thing and Aliens, Hidden Deep puts players on a deep sea mining platform which has suddenly gone dark. A small team of engineers and security personnel are sent down to investigate what happened and get the platform back into operation. Players must move individual team members in side-scrolling fashion through various tunnels and shafts, activating equipment and dispatching the strange creatures which now appear to infest the facility to reach the end goal of each of the ten story missions.
Visually, Hidden Deep is painfully dull. There’s a lot of browns and grays, with some industrial yellow for heavy equipment and reds for the enemies (along with the copious amounts of blood). And a whole lot of black. Lighting effects are not especially subtle for the most part. You’re either going through fluorescent lighting in tunnels or bouncing around with your flashlight. There are few instances of natural or environmental lighting sources, and when they’re used, they’re not exactly awe-inspiring. The scale of the sprites makes fine details which could help the characters pop visually an impossibility. It’s almost as if the developer couldn’t quite decide on making a 16-bit side-scroller homage or a modern high resolution action adventure and tried to split the difference.

“Google Maps doesn’t seem to work down here.”
Sound is something of a mixed bag. On the one hand, you’ve got pretty good sound effects which fit with the setting. Elevators rumble, cranes and rail gondolas whine as they move, and creatures make distinctive noises including the wet splats of their demise when you put a bullet or two in them. But this decent, if workman-like, effort is offset by the tissue thin “soundtrack” and the uninspiring voice work. We don’t even hear one of our hapless troops say anything (strained grunts and death screams don’t count as dialogue) until the last mission.
While Hidden Deep lists Half-Life as an inspiration, the gameplay owes more to The Lost Vikings than anything else, with a hint of Metroid for good measure. Its insistence on moving team members individually means a lot of switching back and forth in missions where there’s more than one character present, which can create problems. Players may be moving through an area that they haven’t yet cleared and need to switch quickly over to the scout (who has the most firepower and bullets, usually), only to watch helplessly as a monster kills them. And if the character you’re controlling dies, the mission restarts basically where they died even if another team member is alive. This scenario is exacerbated when you’re moving through a notionally “cleared” area and enemies respawn for no reason. If this is intended to build tension, the practical upshot is only aggravation.

“I’ve got you covered. I can’t shoot on my own, but I can warn you of trouble by the gurgling screams of me choking on my own blood.”
As a game, Hidden Deep is not a bad tech demo. But it is scandalous, even considering the Early Access label on Steam, that something like this came out in this state. It is the definition of “not ready for prime time,” and any promised future content updates cannot possibly undo the awful first impression it makes.

The game in a nutshell.
Hidden Deep tries to capture the feel of classic horror movies like «The Thing» and «Aliens» in side-scroller form. But the lack of narrative structure, janky controls, uninspiring visuals, and twitchy physics makes for an excruciating experience.Axel Does Not RecommendAbout GameLuster’s Reviews
Post navigation
Operating from a hidden rebel base somewhere in the scorching wilderness of Arizona, Axel has been playing video games longer than he’d care to admit. When he’s not wandering through «Skyrim» for the umpteenth time, he can be found writing his latest novel or hunched over a tabletop and cursing as his d20 comes up a nat 1 yet again.
Оценка этой статьи по мнению читателей:
Казалось бы, что может быть более объективным и неоспоримым, чем технические характеристики устройства?
Разумеется, хороший аккумулятор не всегда означает длительное время работы смартфона, а большое количество мегапикселей — высокое качество фото. Но ведь ёмкость батареи и количество мегапикселей указаны в характеристиках верно. К чему здесь можно придраться?
То же касается практически любой характеристики: экрана, габаритов, памяти и т.д. Никто в здравом уме не будет спорить с тем фактом, что 256 Гб — это вдвое больше, чем 128 Гб.
Но, к сожалению, в реальности всё не так просто и очевидно.
Дело в том, что мы с вами — очень странные и сложные существа. Мы воспринимаем этот мир не таким, каким он является на самом деле. Более того, мы даже не знаем до конца, что такое это «на самом деле».
Но когда мы смотрим на технические характеристики, то относимся к ним так, словно мы не люди, а измерительные приборы. И от этого нами становится легко манипулировать.
В данной статье я бы хотел посмотреть на некоторые характеристики смартфонов с учетом человеческой физиологии. Ведь в нашей с вами реальности 2+2 не всегда равно 4.
Об экране смартфона по-человечески
Начнем с простого примера. На днях Samsung представила новую линейку смартфонов Galaxy S22 в трех модификациях. Помимо прочего, их экраны отличаются своими габаритами, разрешением и яркостью.
Максимальная яркость дисплея младшей модели составляет 1300 нит, а двух других — 1750 нит! У iPhone 13 Pro Max пиковое значение яркости достигает 1200 нит.
Сравнивая эти дисплеи, мы можем сделать такой логический вывод: дисплей Galaxy S22 Ultra на 45% ярче экрана iPhone 13 Pro Max и на треть ярче экрана младшей модели.
А если мы посмотрим на смартфоны в целом, то яркость их экранов может варьироваться от 400 до 1500 нит — какой сумасшедший разброс! Представьте, как на фоне 1500 нит будут выглядеть жалкие 500 нит.
Представили? Отлично! А теперь давайте визуализируем эту информацию. Вот перед вами шкала яркости от 1 до 1500 нит:
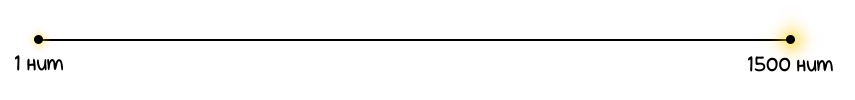
Разумеется, 1 нит — это очень тусклый свет (1 нит равен яркости одной обычной свечи), а 1500 нит — это на 1499 свечей больше, то есть, гораздо ярче!
Теперь давайте отметим на нашей шкале яркость 500 нит. Так как это треть от 1500, то новая отметка будет находиться здесь:
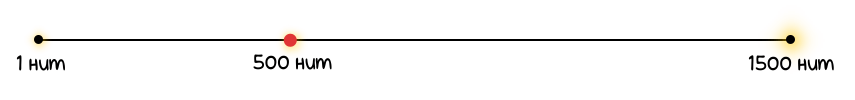
Обратите внимание на пропасть между 500 и 1500 нит. Что более интересно, 500 нит отличаются от минимальной яркости далеко не так сильно, как от максимальной. Судя по этой шкале, мы получим намного бóльшую разницу, сменив 500 нит на 1500, нежели сменив дисплей с яркостью 1 нит на 500 нит.
И тут наше логическое размышление разбивается о причудливую человеческую физиологию.
Логарифмические люди
Разница яркости в 1500 нит — это ничто по сравнению с тем диапазоном яркостей, которые мы можем воспринимать.
К примеру, в ясную ночь при полной луне можно одновременно увидеть как луну, так и очень тусклые звезды (вплоть до третьей величины). Это говорит о том, что в определенных условиях мы можем различить перепад яркостей в миллион раз!
Как же так получается? Как мы можем различать ночью перепады яркости в тысячные доли одного нита и в то же время прекрасно видеть днем, когда яркость предметов, освещенных солнцем, может составлять десятки тысяч нит?
А ведь это справедливо не только для зрения, но и для остальных чувств: обоняния, вкуса, осязания или слуха. Мы без проблем слышим как тихий шепот, так и вой сирены, которая создает звуковое давление, превышающее звук шепота в 100 тысяч раз!
На самом деле секрет таких суперспособностей кроется в том, что мозг использует логарифмы при анализе и обработке информации. И если сформулировать такое поведение одним предложением, то можно сказать следующее:
Чем сильнее стимул, тем больше нужно этого стимула, чтобы почувствовать минимальную разницу
Другими словами, мы без проблем можем почувствовать разницу между двумя смартфонами, которые весят 150 и 200 г. То есть, когда на наши органы чувств влияет слабый стимул (в данном случае — малый вес), мы способны ощущать даже очень небольшие различия.
Но как только стимул становится сильнее, нужно гораздо больше этого стимула, чтобы заметить хоть какую-то разницу. Соответственно, мы уже не сможем ощутить никакой разницы между двумя ноутбуками, массой в 3150 и 3200 г. Хотя эта разница по прежнему составляет 50 грамм.
А если бы мы держали в руках предмет, весом в 50 кг, то никак не почувствовали бы прибавление еще одного килограмма.
То же касается вкуса, яркости, запаха и пр. Даже время мы воспринимаем логарифмически. К примеру, если до конца рабочего дня остается 3 часа и 15 минут, мы прекрасно осознаем и очень точно оцениваем это время.
Но если сказать, что до отпуска осталось 9 месяцев и 5 минут, то наше сознание вообще отбросит минуты как бесполезную информацию. Нам без разницы, осталось ли 9 месяцев и 5 минут или 9 месяцев и 55 минут. Мы физически не способны осознать разницу между этими отрезками времени, как не способны почувствовать разницу между предметами весом 200 и 205 грамм.
Такая особенность человеческой физиологии была сформулирована в конкретный закон под названием закон Вебера — Фехнера.
Так вот, если бы мы решили графически показать восприятие яркости или другого стимула от его реального изменения, то получили бы что-то вроде этого:
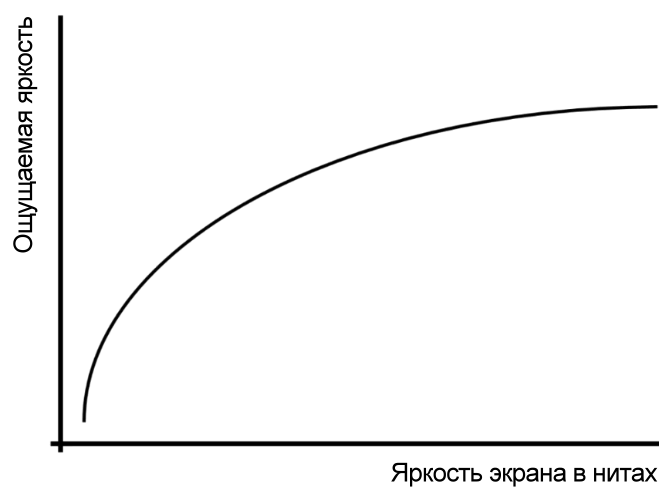
На графике мы наглядно видим, что в начале самые незначительные изменения в реальной яркости (по горизонтали) приводят к большим изменениям воспринимаемой яркости (по вертикали). Но чем выше становится яркость, тем слабее мы ощущаем разницу.
Именно поэтому мы можем различать тысячные доли одного нита ночью.
Если отобразить на этом графике наш пример со шкалой от 1 до 1500 нит, то мы получим примерно следующее (по горизонтали — объективная яркость, измеряемая прибором, а по вертикали — то, что мы видим и ощущаем на самом деле):
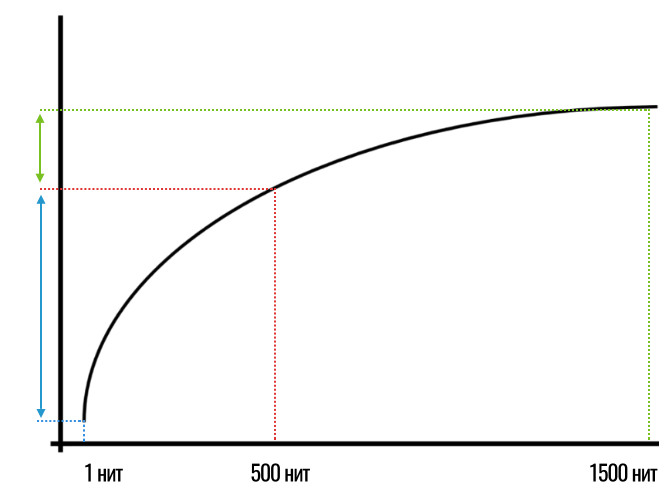
То есть, в реальной жизни всё будет не так, как на шкале, которую мы рисовали в начале. На самом деле мы ощутим гигантскую разницу между 1 и 500 нит яркости (показано синей стрелкой) и намного меньшую разницу между 500 и 1500 нит (показано зеленой стрелкой).
Соответственно, когда реальная (объективная) яркость экрана будет изменяться от 1 до 1500 нит линейно:
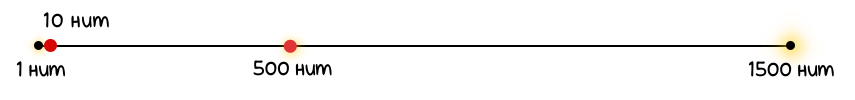
Мы будем воспринимать её в логарифмической шкале, то есть, таким образом:
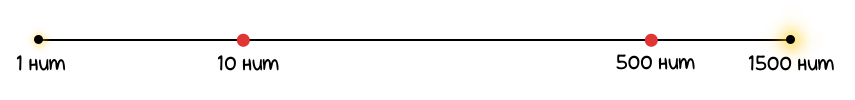
То есть, в реальности мы увидим бóльшую разницу между 1 и 10 нит, чем между 500 и 1500 нит. Хотя в первом случае яркость увеличилась всего на 9 нит, а во втором — на 1000 нит.
Также по этой шкале хорошо видно, что мы можем гораздо лучше различать детали/нюансы при слабом стимуле, так как на меньший физический диапазон (от 1 до 10) выделяется очень широкий «диапазон ощущений».
Что же это говорит нам о такой важной характеристике смартфона, как яркость дисплея?
В характеристиках указывается линейная яркость и нам логически кажется, что экран с яркостью 1600 нит будет в 2 раза ярче экрана с яркостью 800 нит. Тогда как в реальности разница будет намного меньшей.
А если мы говорим о разнице между 1200 и 1300 нит (iPhone 13 и Galaxy S22), то она будет совсем незначительной. Измерительная аппаратура, конечно же, покажет разницу в 100 нит, но для нашего сознания (для нашей реальности) она будет куда менее значимой, чем те же 100 нит разницы между экранами 500 и 600 нит.
Получается, в характеристиках мы видим очень большое преимущество экрана, тогда как в реальности оно может оказаться ничтожно малым.
Поэтому, если бы яркость указывалась «по-человечески», то вместо нит или дополнительно к нитам следовало бы указывать яркость в каких-то относительных (логарифмических) величинах. Чтобы покупатель понимал реальную разницу между двумя экранами, которую он сможет увидеть глазами, а не измерительной аппаратурой.
Да и нет по сути никаких 1750 нит в Galaxy S22 Ultra или 1200 нит в iPhone 13 Pro Max. Получить такое значение можно будет только в очень специфических условиях — при просмотре HDR-фильма, когда на экране будет отображаться крохотный кусочек белого цвета, а в метаданных будет прописана высокая максимальная яркость.
Что касается других параметров экрана, мы уже подробно обсудили некоторые из них в следующих материалах:
О телеобъективе по-человечески
Теперь немножко поговорим о камерах. Как вы знаете, все производители указывают кратность своих телеобъективов или то, во сколько раз они приближают картинку.
Чтобы далеко не ходить за примерами, взглянем на характеристики уже упомянутого выше Galaxy S22 Ultra:

Мы видим, что у смартфона есть два телеобъектива, один из которых приближает изображение в 3 раза, а другой — в 10 раз. И на самом деле здесь нет никакого обмана. Упомянутые объективы действительно имеют такую кратность.
Так в чем же подвох?
Всё дело в том, как именно мы воспринимаем фразу «в 10 раз». Нам подсознательно кажется, что речь идет о возможности приблизить видимый нами объект в 10 раз. То есть, мы видим маленькую луну на ночном небе и думаем, что смартфон с 10-кратным зумом увеличит её изображение в 10 раз.
Другими словами, подавляющее большинство пользователей относятся к телеобъективу смартфона как к биноклю или подзорной трубе, которые увеличивают изображение во столько раз, во сколько заявлено в характеристиках.
Но с чего вы взяли, что производитель имел в виду «в 10 раз относительно того, что видит человек невооруженным глазом»?
На самом деле в характеристиках всегда указывается кратность телеобъектива относительно основной камеры смартфона, а не человеческого глаза. То есть, если основная камера «видит» объект размером X, то 3-кратный телеобъектив увеличит этот объект до размера 3X, а десятикратный — 10X (в 10 раз).
Проблема лишь в том, что основная камера любого смартфона «видит» все объекты размером вдвое меньше того, что видит человек. То есть, наш глаз уже является «2-кратным телеобъективом» по отношению к основной камере любого смартфона.
Поэтому, когда мы видим на каком-нибудь iPhone 12 Pro двукратный телеобъектив, то должны понимать, что на самом деле этот объектив не приближает картинку в 2 раза. Он «видит» размеры объектов и перспективу такими, какими их видим мы невооруженным глазом.
Соответственно, 10-кратный телеобъектив Samsung Galaxy S22 Ultra в реальности увеличивает картинку лишь в 5 раз! То есть, если мы хотим воспользоваться 10-кратным объективом смартфона как «подзорной трубой», то это будет труба с 5-кратной оптикой. И приближать она будет объекты в 5 раз, а не 10. Соответственно, 3-кратная оптика iPhone 13 Pro Max не сможет увеличить наблюдаемый нами объект и в 2 раза.
Повторюсь, формально производитель никого не обманывает. Оптический зум 10x действительно увеличивает изображение в 10 раз относительно того, что «видит» основная камера смартфона.
Но если бы эта характеристика указывалась «по-человечески», тогда рядом с «10x» следовало бы для телеобъективов указывать его кратность как бинокля или подзорной трубы, чтобы человек осознавал, во сколько раз он сможет приблизить ту же луну.
С другой стороны, приближение и кратность еще усложняются тем фактом, что мы не просто смотрим в камеру смартфона как в подзорную трубу. На выходе мы получаем снимок и объекты на снимке можно дополнительно увеличивать, если разрешение фотографии достаточно высокое.
Другие характеристики
На самом деле, в технических характеристиках еще много подводных камней.
Это касается и «уровня излучения» смартфона (SAR), на который многие обращают внимание и выбирают аппарат, в котором это число меньше, тем самым попадая в интересную ловушку.
Если понимать сам процесс тестирования и определения уровня излучения, то число SAR фактически говорит лишь о том, что смартфон успешно прошел испытание и является безопасным с точки зрения науки, а не о том, какое влияние он будет оказывать на ткани тела.
Также у многих людей есть проблемы с пониманием громкости звука. Не так давно на одном популярном техно-сайте автор писал такой любопытный текст:
Если же перевести этот текст на человеческий язык, то автор сказал буквально следующее: динамик Motorola Edge+ будет в 64 раза громче динамиков обычных смартфонов. Но компания-то заявила всего лишь о 60%, что даже не в 2 раза громче. А всё дело снова в логарифмической шкале.
Но о звуке мы обязательно поговорим в другой раз, так как звук — это не только динамики. Многие пользователи ищут хороший смартфон для прослушивания музыки в наушниках и обращают внимание на ЦАП, усилитель и другие неочевидные характеристики.
Алексей, главред Deep-Review
The future of deep learning
Unsupervised learning Reinforcement learning (basic principles of alpha go) Reinforcement learning does not require data with correct input/label pairs. It focuses more on online planning and needs to find a balance between exploration (unknown domain) and compliance (existing knowledge) , The learning process is that the agent constantly interacts with the environment, and it is a repeated practice process of trial and error. Reinforcement learning is different from supervised learning in that there is no supervisor, only one reward signal, and feedback is delayed, not immediately generated, so time (sequence) is important in reinforcement learning significance. gan (Generated confrontation network proposed in 2014)


Unsupervised learning: It can be said that it is the research on unsupervised learning that has catalyzed the renaissance of deep learning. However, now unsupervised learning seems to have been overshadowed by the great light of supervised learning. Considering that most people and animals understand the world through unsupervised learning, in the long run, the research on unsupervised learning will become more and more important. The combination of deep learning and reinforcement learning: On the basis of CNN and RNN, combined with Reinforcement Learning to let the computer learn to make further decisions. Although research in this area is still in its infancy, there have been some impressive results. For example, AlphaGo some time ago. Natural language understanding. Although RNN has been widely used in natural language processing, there is still a long way to go in teaching machines to understand natural language. The combination of feature learning and feature inference. This may greatly promote the development of artificial intelligence
annex:deepLearning original and translation
Recurrent Neural Network (RNN)
RNN features: (neural network with storage function)

RNN connects parameter values at each time point, and there is only one copy of the parameter In addition to input, the neural network will be built on the basis of previous «memory» The memory requirement is related to the input scale LSTM (Long Short-term Memory) (is a special RNN and also a threshold RNN. It is mainly used to solve the problem of gradient disappearance and gradient explosion in the training process of long sequences, which is better than ordinary RNN It has better performance, can handle longer sequences, and can remember more related hidden-layer and intermediate results)

Recurrent Neural Network (Recurrent Neural Network) is usually used to process some sequence of input (such as speech or text). Its basic idea is to process only one element in the input sequence at a time, but maintain a state vector in hidden units to implicitly encode the historical information previously input. If we expand the hidden units at different moments in space, we get a (time) deep network. Obviously, we can use the backpropagation algorithm to train an RNN model on this deep network. In the RNN model, the state vector at each moment is determined by the state vector at the previous moment and the input at the current moment. In this recursive way, RNN maps the input at each moment into an output that depends on all inputs in its history. Note that the parameter () in the model is a weight that has nothing to do with the sequence time. RNN has many applications in natural language processing. For example, an RNN model can be trained to «encode» a segment of English into a semantic vector, and then another RNN model can be trained to «decode» the semantic vector into a segment of French. This realizes a translation system based on deep learning. In addition, in the «encoding» stage, we can also use a deep convolutional network to convert an original picture into advanced semantic features, and on this basis, train an RNN «decoder» to achieve » «Look at pictures and speak» function. Although the original intention of RNN design is to learn long memory dependence, some theoretical and experimental studies have shown that «it is difficult to learn to store information for very long». For this reason, people proposed the long short-term memory (LSTM) model. The LSTM model controls the balance of long and short-term memory by introducing some special interneurons (gate variables) on the basis of the RNN model. It has been proved to be more efficient and powerful than the traditional RNN model. There is another type of model that enhances the memory capacity of the RNN model by introducing a memory storage unit. Neural Turing Machine and memory networks are such models. They have proved to be very effective in inference systems that deal with some knowledge questions and answers.
Convolutional Neural Network
What is CNN?
- One neuron cannot see the entire picture
- Able to reach small areas with fewer parameters
- Picture compression pixels do not change the picture content
CNN’s secret to reducing parameters Generally speaking, a single-layer neural network can represent any function; convolution can greatly reduce parameters, improve efficiency, and reduce complexity
Supervised learning
Supervised learning, supervised learning, is a common form of machine learning. Its task is to train a model so that it can output the expected value under a given input. To this end, we need an error function to calculate the error between the output value and the expected value, and reduce this error by adjusting the internal parameters of the model. Gradient Descent and Stochastic Gradient Descent (SGD) are two common parameter adjustment algorithms. Currently, for supervised learning problems, most machine learning systems run a linear classifier on manually selected features. However, the disadvantage of a linear classifier is that it can only divide the input space into some simple regions, so it is often powerless in issues such as image recognition and language recognition (these problems require the model to be extremely sensitive to small changes in some specific features, And extremely insensitive to changes in irrelevant features). For example, at the pixel level, the difference between the two pictures of the same Samoyed in different backgrounds is very large, while the difference between the pictures of Samoyed and Wolf in the same background is very small. For the traditional linear classifier, or any shallow classifier, I want to distinguish between Samoyed and Wolf in the latter group of pictures, and put Samoyed in the previous group of pictures under the same category. It is almost an impossible mission. This is also called selectivity–invariance dilemma: we need a set of features that can selectively respond to important parts of the picture, while maintaining invariance to changes in unimportant parts of the picture. The traditional solution to this problem is to manually design some feature extractors. However, with Deep Learning, we hope to learn these features spontaneously from data.
Request a demo
Are you an expert?
Login
Distributed representation and language types

word embedding (converting text data into numerical data: that is, a word in the text space is mapped or embedded into another numerical vector space by a certain method). The machine reads documents through a large number of Get its meaning one-hot embedding (Use the position of the word in the dictionary to indicate the meaning of the word) Word2Vec algorithm (skip-gram: given input to predict context, this algorithm was proposed in 2013)

Deep learning theory points out that compared with traditional shallow learning models, deep learning networks have two exponential advantages: Distributed representation makes the generalization space of the model grow exponentially (even samples that do not appear in the training space can be combined by distributed features); The characteristic expression of the hierarchical structure accelerates this exponential growth in depth. Here is an application of deep neural network in natural language processing to explain the concept of distributed representation. Suppose we need to train a deep neural network to predict the next word in a text sequence. We use a one-of-N 0-1 vector to represent words that appear in the context. The neural network will first generate a word vector for each input 0-1 vector through an embedding layer, and convert these word vectors into word vectors of target words through the remaining hidden layers. The word vector here is a distributed representation. Each element in the vector corresponds to a certain semantic feature of the original word. These features are not mutually exclusive and collectively express the words in the original text. It should be noted that these semantic features neither explicitly exist in the original input data, nor are they specified in advance by experts, but are automatically mined from the structural connections of input and output through neural networks. Therefore, for our word prediction problem, the word vector learned by the model can well represent the semantic similarity of two words (for example, in this problem, the word vectors given by the two words Tuesday and Wednesday are similar Degree is very high). The traditional statistical language model is difficult to achieve this (they usually treat the word as an indivisible smallest unit). Nowadays, this technology of learning word vector from text is widely used in various natural language processing problems.
Have a look at Deep Review
https://youtube.com/watch?v=w9y0xRVGFY8%3Fautoplay%3D0%26start%3D0%26rel%3D0
They trust us
- The public service company uses Deep Review to improve the customer experience in its branches by deciphering the weak signals of customer perception.
- French energy company
To improve customer satisfaction and understand areas for improvement in its service offering, this energy specialist relied on Deep Review to conduct an analysis of satisfaction surveys. - French governmental entity
To better target health risk establishments and better protect the consumer, Deep Review helped leverage online customer reviews to automate the detection of health and hygiene non-compliance in food and beverage establishments.
Request a demo
Our publications
DocReview, one of Sia Partners’ AI solutions, automatically reads thousands of documents of any format (pdf, scan, etc.) and extracts the key information they contain.
While AIs continue to break new records, a quieter revolution is taking shape in the Big Data sphere: the open data revolution.
Image understanding based on deep convolutional neural network
Although as early as 2000, convolutional neural networks have achieved good results in the field of image recognition; but it was not until the 2012 ImageNet competition that CNN was accepted by mainstream scientists in computer vision and machine learning. The rise of CNN depends on four factors: GPU’s high-performance computing; the proposal of ReLU; a regularization technique called dropout; and a technique that transforms existing data to generate more training samples. A deep convolutional neural network usually has 10-20 convolutional layers with hundreds of millions of weights and connections. Thanks to the rapid development of computing hardware and parallel computing, the training of deep convolutional neural networks has become possible. Today, deep CNN has brought a revolution in the field of computer vision, and is widely used in almost all tasks related to image recognition (such as autonomous driving of unmanned vehicles). A recent study showed that if the high-dimensional features learned by deep CNN are combined with RNN, the computer can even be taught to «understand» the content in the picture.