

Общее описание схемы и подготовка underlay
В фабрике будет использоваться 2 Spine и 4 Leaf (2 из которых объединены в m-lag пару). Между Spine и Leaf коммутаторами используются point to point подсети с 31 маской и увеличен MTU. Используется симметричный IRB. Spine коммутаторы так же будут выполнять роль BGP route reflector. Инкапсуляция и деинкапсуляция будет производиться на Leaf коммутаторах.
Начну с настройки m-lag пары leaf коммутаторов, для правильной работы нужен keepalive линк и peer линк. По peer линку может идти полезная нагрузка поэтому необходимо учитывать полосу пропускания этого линка. Так же следует учитывать, что m-lag в исполнении Huawei накладывает некоторые ограничения, например нельзя построить ospf соседство через агрегированный интерфейс (или можно но с костылями):
dfs-group 1 priority 150 source ip 192.168.1.1 # IP адрес keepalive линка
#
stp bridge-address 0039-0039-0039 #для правильной работы STP задаем одинаковый bridge id
#
lacp m-lag system-id 0010-0011-0012 #задаем system id для LACP
#
interface Eth-Trunk0 #создаем peer линк trunkport INTERFACE #добавляем интерфейс в LAG stp disable mode lacp-static peer-link 1
#
interface Eth-Trunk1 #пример агрегированного интерфейса в сторону сервера например mode lacp-static dfs-group 1 m-lag 1Проверяем, что m-lag пара собралась:
Пример настройки интерфейса внутри фабрики:
interface GE1/0/0
undo portswitch #переводим интерфейс в режим L3
undo shutdown #административно включаем интерфейс
ip address 192.168.0.1 31
ospf network-type p2p #меняем тип OSPF интерфейса на point-to-point mtu 9200 #увеличиваем MTU интерфейсаВ качестве underlay протокола маршрутизации используется OSPF:
ospf 1 router-id 10.1.1.11
area 0.0.0.0
network 10.1.1.1 0.0.0.0 #анонсируем anycast lo только с m-lag пары network 10.1.1.11 0.0.0.0
network 192.168.0.0 0.0.255.255Так же в качестве протокола маршрутизации можно использовать два BGP процесса, один для underlay маршрутизации и второй для overlay маршрутизации.
bgp AS_UNDERLAY #процесс для underlay маршрутизации <settings>
bgp AS_OVERLAY instance EVPN_NAME #процесс для overlay маршрутизации <settings>С базовыми настройками закончили, проверим, что OSPF собрался и маршруты балансируются между Spine коммутаторами.
Соседство собралось, проверим маршрутную информацию:
Что интересного на уровне модуля
Конструкционно все современные СХД от любого производителя выглядят одинаково: во фронтальную часть стального коробчатого шасси устанавливаются контроллеры, в тыльную — интерфейсные модули. Есть еще блоки питания и вентиляции. Казалось бы, все привычно и стандартно. Но на самом деле мы внедрили в эту парадигму много всего интересного.
Начнем с монтажа элементов системы хранения в шасси. Магнитных 3,5-дюймовых дисков в СХД становится меньше, начинают преобладать гибридные системы и all-flash. Но даже несколько дисковых накопителей с частотой вращения шпинделя до 15 тысяч оборотов в минуту создают вибрацию, которую нельзя не учитывать.
Пусть даже на какие-то доли процентов, но на надежность это влияет. А в масштабе крупного ЦОДа доли процентов на один накопитель превращаются в ощутимые показатели отказов и сбоев. Чтобы вибрация отдельных дисков в меньшей степени передавалась через жесткую конструкцию шасси, салазки под диски мы оборудуем резиновыми или металлическими демпферами.
Для шпиндельных накопителей минимальная тряска — уже проблема: головки начинают сбиваться, производительность существенно падает. SSD – другое дело, вибрации они не боятся. Но надежная фиксация компонентов по-прежнему важна. Взять процесс доставки: ящик могут уронить или небрежно швырнуть, поставить боком или вверх тормашками.
Когда-то давно мы начинали с разработки вычислительной техники для телеком-индустрии, где стандарты работоспособности по температуре и влажности традиционно высоки. И мы перенесли их и на другие направления: металлические детали СХД не окисляются даже при повышенной влажности – за счет применения никелирования и оцинковки.
Тепловой дизайн наших СХД разрабатывался с упором на равномерность распределения температуры по шасси – чтобы не допустить ни перегрева, ни слишком сильного охлаждения какого-либо угла дисковой полки. Иначе не избежать физической деформации – пусть даже незначительной, но все-таки нарушающей геометрию и способной привести к сокращению срока работы оборудования. Таким образом выигрываются какие-то доли процента, но на общую надежность системы это все-таки влияет.
Huawei cloudengine 6800: обзор и опыт использования

Центральным звеном любой ИТ-инфраструктуры, коммерческой организации, гос.компании или облачного хостинг-провайдера является сетевая инфраструктура. Основными TOR коммутаторами в нашей инфраструктуре являются коммутаторы Huawei CloudEngine 6800.
Команда проекта mClouds.ru имеет достаточно серьёзный опыт в технологиях, тем не менее, именно их практическое применение, в качестве конечного эксплуататора, имеет свои особенности. Поэтому, накопив опыт, спустя год мы запустили свой блог на Хабре, дабы делиться своим опытом и практиками в процессе работы.
Запуская проект по предоставлению в аренду виртуальных ресурсов, мы применяли актуальные дизайн гайды от различных вендоров, включая Huawei NDG (Network-Design Guide) и CVD (Cisco Validated Design Program), которые являются руководством по построению оптимальных и защищённых сетей уровня дата-центр.
Краткая информация о CloudEngine

Минутка маркетинга: В 2022 компанией Huawei была представлена линейка коммутаторов CloudEngine (далее CE), которая разработана для центров обработки данных и высокопроизводительных кампусных сетей. Флагманом в этой линейке является CE 12800 с одной из самой высокой в мире производительностью
Краткая информация по портам в линейке CE
Ключевой компонент в линейке, это решения для ЦОД Huawei Cloud Fabric Solutions. Это платформа для построения SDN (software-defined networking) DC (datacenter) с возможностью интеграции со средой VMware по протоколу OVSDB (Open vSwitch Database, RFC 7047). Данная интеграция позволяет сократить эксплуатационные расходы и трудозатраты, связанные с управлением и развертыванием услуг и сервисов на платформе виртуализации VMware. Подробнее про Cloud Fabric вы можете прочитать в блоге Huawei на Хабре.
Облачный движок
В качестве коммутаторов доступа мы используем Huawei CloudEngine 6800 (CE6810-48S4Q-LI), которые обеспечивают высокую плотность портов 10GE (48 x 10 GE SFP ) с возможностью стекирования и подключения к ядру сети с помощью портов 40GE (4 x 40 GE QSFP ).

Краткие характеристики CE6810
Краткая информация о различиях версиях коммутаторов EI и LI.
Подробные характеристики доступны по следующей ссылке:
huawei.com
iStack
В качестве примера, хотели бы продемонстрировать конфигурацию iStack на базе Huawei CE6810. При использовании iStack возможно объединение в стек до 16 коммутаторов (поддерживаемые прошивки V100R003C10 и позднее) c помощью портов 10GE, 40GE и 100GE. Дополнительное лицензирование iStack не требуется.
Преимущества технологии iStack
1. Упрощенное управление и конфигурирование: устройства в стеке являются одним логическим устройством. Управление коммутаторами возможно с любого участника стека.
2. Резервирование Control Plane: каждый коммутатор оснащён двумя MPU, где master обрабатывает запросы, а standby работает, как резервная копия master, и постоянно выполняет синхронизацию с ним. В случае выхода из строя master, standby становится основным и продолжает обрабатывать сервисные пакеты. Технология iStack реализует избыточность 1:1. В стеке один главный коммутатор обрабатывает сервисные пакеты, а один standby коммутатор функционирует как резервная копия master коммутатора и синхронизирует информацию с ним. Другие коммутаторы в стеке являются slave, когда master выходит из строя, standby становится master, а из slave выбирается новый standby коммутатор. Данная схема с slave коммутаторами позволяет дополнительно повысить надёжность системы.
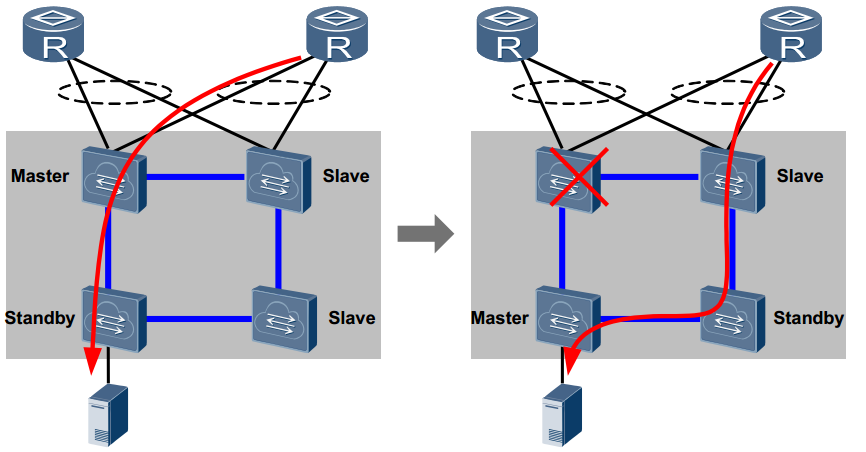
Путь трафика через до и после смены Master
3. Резервирование uplink и downlink

4. Резервирование линков и интерфейсов: в кольцевой топологии при падении линка топология становится последовательной, а агрегация нескольких интерфейсов позволяет повысить отказоустойчивость и увеличить общую пропускную способность интерфейсов.
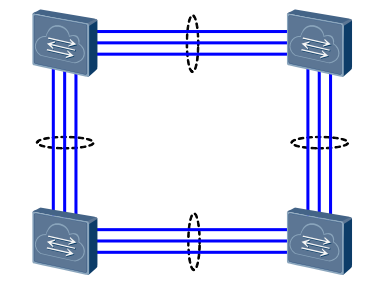
Отказоустойчивость стек-портов и интерфейсов
Основные понятия
Роли коммутаторов – коммутаторы в стеке классифицируются следующими ролями:
— Master – главный коммутатор в стеке. Один на стек.
— Standby – резервный коммутатор. В стеке может быть только один standby.
— Slave – подчинённый коммутатор, максимальное количество: N-2, где N – максимальное количество коммутаторов в стеке.
Stack domain – область в которой коммутаторы объединены в одно логическое устройство. Несколько доменов могут быть объединены.
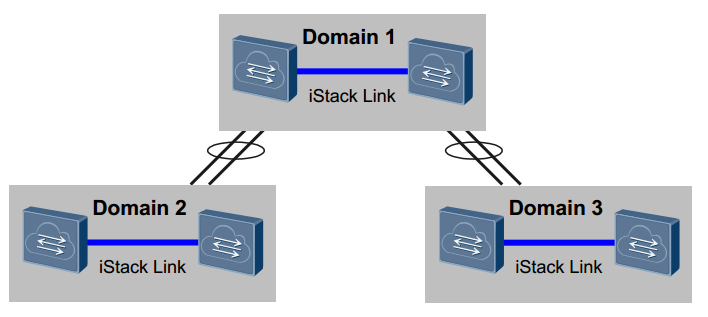
Stack ID – идентификатор для определения коммуаторов, иначе member ID, данные ID являются уникальными в стеке.
Stack priority – приоритет коммутатора, один из параметров на основе которого производится выбор ролей коммуатора.
Physical member interface – физические порты, которые задействуются в стеке между коммутаторами.
Stack interface – логический интерфейс, который объединяет физические порты в виртуальный интерфейс, именуются как stack-port N/1, stack-port N/2.
Топологии
Стекирование возможно с помощью двух топологий: последовательное (chain) и кольцо (ring).

Топология chain
Преимущества последовательного соединения это стекирование коммутаторов на больших расстояниях (до 16 коммутаторов). Из минусов можно отметить недостаточную надёжность и низкую эффективность использования полосы пропускания.

Топология ring
Плюсы топологии кольца — это высокая надежность и высокая пропускная способность стека.
Определение master коммутатора
Выбор мастера происходит по следующему сценарию:
1. Running status: первый коммутатор, который был запущен и добавлен в iStack становится Master
2. Stack priority: коммутатор с наивысшим приоритетом становится Master
3. Software version: коммутатор с новейшей прошивкой становится Master
4. Mac: коммутатор с наименьшим MAC-адресом становится Master
Добавление и удаление коммутатора из стека
Добавление нового коммутатора в стек:
1. Если коммутатор не задействован в каком-либо другом стеке (нет уникальной метки stack ID), то он становится slave.
2. Если коммутатор ранее был в стеке A, то master выбирается из двух коммутаторов с ролями master в стеках A и B. Коммутатор получивший роль master, например, из стека B, синхронизирует коммутаторы из стека A (выполняется перезагрузка и синхронизация данных с новым стеком), остальные роли остаются неизменны.
Отключение коммутатора:
1. Если master коммутатор отключается, то standby становится master. Обновляется топология и выбирается новый standby
2. Если standby коммутатор отключается, происходит обновление топологии и выбирается новый standby
3. Если slave коммутатор отключается, то обновляется стек топология
4. Если master и slave коммутаторы отключаются, то все коммутаторы перезагружаются и образуют новый стек
Конфигурирование
Настройка стека происходит в несколько этапов:
0. Проверка совместимости ПО и коммутаторов
1. Предварительная настройка участников стека
2. Настройка портов входящих в стек интерфейс
3. Проверка конфигурации
4. Сохранение конфигурации и перезагрузка
5. Подключение физических кабелей
6. Включение коммутаторов
Для демонстрации технологии iStack на тестовом стенде мы используем два коммутатора линейки CE6810.
0. Перед конфигурированием рекомендуем обратиться к iStack Assistant для получения информации по требуемым версиям прошивок и возможностям стекирования.
Примечание: в случае, если master имеет новую версию прошивки, то slave коммутаторы автоматически синхронизируют версию ПО, выполнят перезагрузку и после будут добавлены в стек.
1. Установка параметров стека на коммутаторах
a. Конфигурация коммутатора SW01
> system-view
[~HUAWEI] sysname SW01
[*HUAWEI] commit
[~SW01] stack
[~SW01-stack] stack member 1 priority 150
[*SW01-stack] stack member 1 domain 100
[*SW01-stack] quit
[*SW01] commit b. Конфигурация коммутатора SW02
> system-view
[~HUAWEI] sysname SW02
[*HUAWEI] commit
[~SW02] stack
[~SW02-stack] stack member 1 renumber 2 inherit-config
Warning: The stack configuration of member ID 1 will be inherited to member ID 2 after the device resets. Continue? [Y/N]: y
[*SW02-stack] stack member 1 domain 100
[*SW02-stack] quit
[*SW02] commit После стекирования устройств потребуется перезагрузка. Описание команд:
system-view — переход в привилегированный режим
sysname — указание hostname коммутатора
commit — применение внесенных изменений
stack — переход в режим конфигурации стека
stack member priority <1-255>- установка приоритета для коммутатора
stack member domain <1-65535>- установка domain_ID
stack member renumber inherit-config — добавление коммутатора с уникальным member_ID. Указание inherit-config наследует исходную конфигурацию стека после рестарта, иначе будет скачана конфигурация с Master коммутатор.
Примечание: если коммутатор с ролью slave будет иметь одинаковый ID с master, то master назначит коммутатору уникальный ID.
2. Конфигурация стек-портов

a. Конфигурация портов на коммутаторе SW01
[SW01]interface stack-port 1/1
[SW01-stack-port1/1]port member-group interface 40GE 1/0/1 to 40GE 1/0/2b. Конфигурация портов на коммутаторе SW02
[SW02]interface stack-port 1/1
[SW02-stack-port1/1]port member-group interface 40GE 1/0/1 to 40GE 1/0/2Описание команд:
interface stack-port /<1-2> — создание группы стек-портов
port member-group interface 40GE to 40GE — добавление портов коммутатора в стек-порт
3. Проверка конфигурации
[SW01]display stack config
Oper : Operation
Conf : Configuration
* : Offline configuration
Attribute Configuration:
-----------------------------------------
MemberID Domain Priority
Oper(Conf) Oper(Conf) Oper(Conf)
-----------------------------------------
1(1) --(100) 100(150)
-----------------------------------------
Stack-Port Configuration:
------------------------------------------
Stack-Port Member Ports
------------------------------------------
Stack-Port1/1 40GE1/0/1 40GE/1/0/2
-----------------------------------------4. Сохранение конфигурации и перезагрузка устройств
> save
Warning: The current configuration will be written to the device. Continue? [Y/N]: y
> reboot
Warning: The system will reboot. Continue? [Y/N]: y5. Физическое подключение кабелей стекирования
Так как в нашей конфигурации мы используем два коммутатора, выполняем подключение согласно топологии Chain.
6. Проверка конфигурации
> display stack
--------------------------------------------------------------------------------
MemberID Role MAC Priority DeviceType Description
-------------------------------------------------------------------------------- 1 Master 0004-yyyy-yyyy 150 CE6810-48S4Q-LI
2 Standby 0004-xxxx-xxxx 100 CE6810-48S4Q-LI
-------------------------------------------------------------------------------- indicates the device through which the user logs in. Кошководам
Для создания окружения а-ля «IOS like» предусмотрена возможность создания алиасов (псеводним). С помощью псевдонимов возможно сделать удобное окружение, сэкономить на времени ввода команды для часто используемых команд.
Формат команды alias
alias [ parameter ] command «»
Список используемых нами алиасов
] command alias
-cmdalias] alias show command "display"
-cmdalias] alias exit command "quit"
-cmdalias] alias no command "undo"
-cmdalias] alias write command "save"
-cmdalias] alias config command "system-view"Просмотр созданных алиасов:
] display command alias
Удаление неиспользуемых алиасов:
] command alias
-cmdalias] undo alias %alias
Сравнение с Cisco
Один из самых интересных пунктов выбора, а какие отличие от других? С помощью Analyze Product Advantages от Huawei мы можем узнать, что коммутатор CE6810 компания Huawei может сравнивать со следующими моделями:
К сожалению данные модели являются Fabric Extenders, которыми возможно управлять с Cisco Nexus 5K и 7K, поэтому не брать рассматривать, а возьмём в расчёт Nexus 3K (Nexus 3172PQ), который является аналогом Huawei CE6851-48S6Q-HI.
Заключение
За продолжительное время работы у инженерного подразделения команды VPS и IaaS провайдера mCloduds.ru сложилось положительное мнение о линейке Huawei CloudEngine:
многофункциональность, оперативная работа службы технической поддержки, подразделение которой присутствует на территории России, простота управления и многое другое. Это позволяет обеспечивать высокую доступность к вычислительной среде наших клиентов.
Для получения дополнительной информации по линейке Huawei CloudEngine и другим решениям, вы можете обратиться к нам по электронной почте info[at]mclouds.ru, будем рады вам помочь 🙂
Oceanstor os
Функционал СХД контроллеров Huawei основывается на OceanStor OS – закрытой модульной Unix like ОС Huawei. В целом функционал сильно схож с RAID-контроллерами, но добавлен ряд фич.
Есть базовый функционал (Basic function control software) и есть функционал дополнительный (Value-added function control software), который докупается в виде лицензионных ключей. В ПО СХД ОС заложено много инструментов по backup/monitoring/восстановлению данных на ЖД (ЖД самый частый сбойный компонент СХД т.к. это элемент с механической компонентой).
Архитектура OceanStor OS
Raid 2.0
Отказоустойчивый дизайн в СХД мы продумали и на уровне системы. Наша технология Smart Matrix представляет собой надстройку поверх PCIe – эта шина, на основе которой реализованы межконтроллерные соединения, особенно хорошо подходит для SSD.
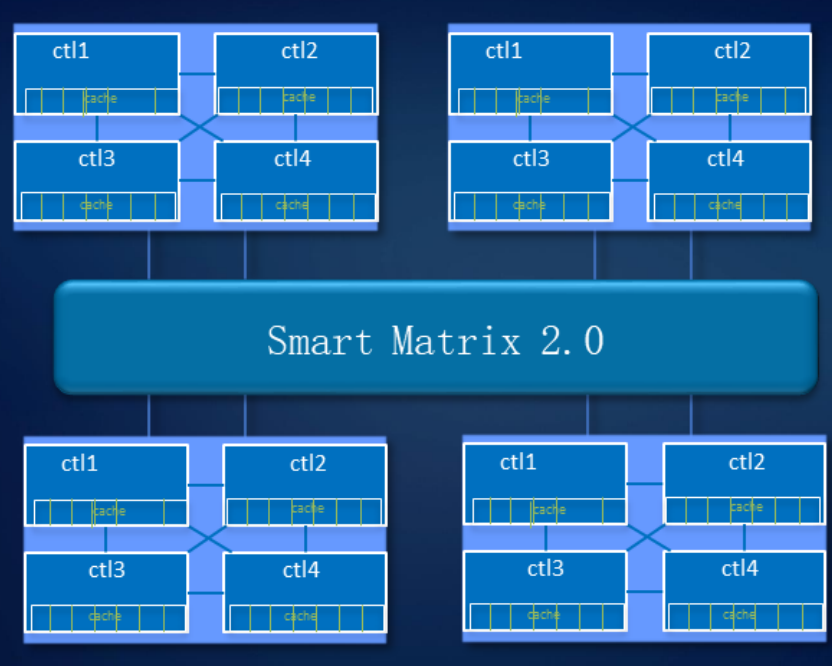
Smart Matrix обеспечивает, в частности, 4-контроллерный full mesh в нашем СХД Ocean Store 6800 v5. Для того чтобы каждый контроллер имел доступ ко всем дискам в системе, мы разработали особый SAS-бэкэнд. Кэш, естественно, зеркалируется между всеми активными в данный момент контроллерами.
Когда происходит сбой контроллера, сервисы с него быстро переключаются на контроллер зеркала, а оставшиеся контроллеры восстанавливают взаимосвязь, чтобы зазеркалить друг друга. В то же время данные, записанные в кэш-память, имеют зеркальный резерв для обеспечения надежности системы.
Система выдерживает отказ трех контроллеров. Как показано на рисунке, при отказе элемента управления A данные кэша контроллера B будут выбирать контроллер C или D для зеркального отображения кэша. Когда выходит из строя контроллер D, контроллеры B и C делают зеркальное отображение кэша.
Система распределения данных RAID 2.0 – стандарт для наших СХД: виртуализация на уровне дисков давно пришла на смену безыскусному поблоковому копированию содержимого с одного носителя на другой. Все диски группируются в блоки, те объединяются в более крупные конгломераты двухуровневой структуры, а уже поверх ее верхнего уровня строятся логические тома, из которых составляются RAID-массивы.
Основное преимущество такого подхода – сокращенное время перестроения массива (rebuild). Кроме того, в случае выхода из строя диска перестроение производится не на стоявший все это время «под паром» (hot spare) диск, а на свободное место во всех используемых дисках.
Нормальная скорость восстановления RAID составляет 30 МБ / с, поэтому для восстановления данных объемом 1 ТБ требуется 10 часов. RAID 2.0 сокращает это время до 30 минут.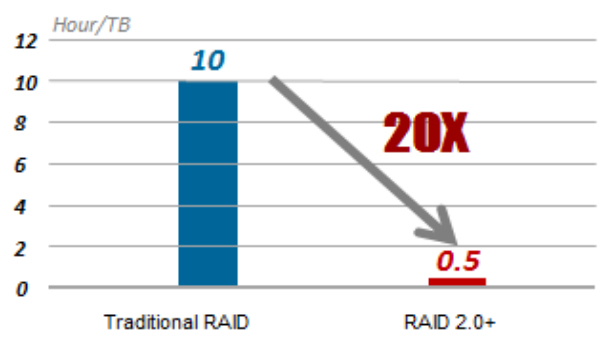
Нашим разработчикам удалось добиться равномерного распределения нагрузки между всеми шпиндельными накопителями и SSD в составе системы. Это позволяет раскрыть потенциал гибридных СХД гораздо лучше, чем привычное использование твердотельных накопителей в роли кэша.
В системах класса Dorado мы реализовали так называемся RAID-TP, массив с тройной четностью. Такая система продолжит работать при одновременном выходе из строя любых трех дисков. Это повышает надежность по сравнению с RAID 6 на два десятичных порядка, с RAID 5 — на три.
RAID-TP мы рекомендуем для особо критичных данных, тем более что благодаря RAID 2.0 и высокоскоростным flash-накопителям на производительность это особого влияния не оказывает. Просто нужно больше свободного пространства для резервирования.
Как правило, системы all-flash используют для СУБД с маленькими блоками данных и высоким IOPS. Последнее не очень хорошо для SSD: быстро исчерпывается запас прочности ячеек памяти NAND. В нашей реализации система сперва собирает в кэше накопителя сравнительно крупный блок данных, а затем целиком записывает его в ячейки.
Добавить в bcmanager массивы и vcenter с обеих площадок в bcmanager
1. Сначала необходимо создать сами площадки в разделе Resources -> Create Site. Здесь просто задаём им имена.
2. Для каждой площадки нужно создать хотя бы одну СХД и один хост.
3. Следующий этап — создание Protected Group, в которую будут входить VM, которые мы собираемся защищать.
Нажимаем OK. следующем окне — Next, проверяем параметры и задаём имя.
Мы настроили репликацию на самом массиве, создали политику для нашей тестовой машины. В разделе Protection можно убедиться, что она работает.
А если перейти на главную страницу BCManager, вы увидите анимацию репликации данных между площадками.
Но вернёмся к нашей задаче. DR-план создан, и теперь будет логично его проверить. Мы уже убедились, что реплика проходит, теперь нужно протестировать план восстановления. Он создается автоматически и находится в разделе Utilization > Data Restore.
Нажимаем Test и указываем, на какой площадке будет произведено тестовое восстановление.
На вкладке Test Network необходимо сопоставить сеть продуктивного кластера с сетью в тестовом кластере для нашей VM. По окончании процесса открываем вкладку Execution Records и видим, что DR-план запустил VM менее, чем за 5 минут. В моём случае дольше всего заняло конфигурирование датасторов на резервной площадке.
Посмотрим на VM со стороны VMware.
И на наш снепшот луна со стороны СХД, примапленый к тестовому кластеру.
Дополнительно можно зайти в VM, проверить, что сервисы на ней работают, данные консистентны и всё в порядке. Мы убедились, что DR отработал. Что дальше? Необходимо очистить DR-площадку от тестовой машины, т.к. в текущем состоянии мы не сможем запустить DR-план. В разделе Utilization > Data Restore у плана восстановления нажимаем More > Clear.
Давайте теперь проведём боевую миграцию. Разберём этот процесс на основе Planned migration. Во-первых, он выполняет больше действий по сравнению с аварийным переключением, во-вторых, работает из-за этого чуть дольше, а для нас важно понять время RTO.
Итак, весь процесс переключения занял чуть менее 6 минут.
На процесс переключения больше всего влияет количество хостов в кластере, как в исходном, так и в целевом. В больших кластерах, с большим количеством имеющихся датасторов, время переключения может составить и час.
Последнее действие, которое нужно сделать после Planned migration, это Reprotection — разворачивание реплики СХД в обратную сторону, т.к. продуктивная VM переехала в другой ЦОД.
Теперь немного о грустном, куда же без этого?
Dorado V6 на текущий момент не поддерживает технологию HyperVault, поэтому на DR-площадке хранится только одна копия данных. Представим простую ситуацию — мы делаем репликацию раз в час, ночью приходит шифровальщик и выводит из строя данные на каком-то из серверов. Утром это обнаруживает администратор, и всё, что ему остаётся, — восстанавливать сервер из резервной копии, т.к. на вторую систему мы уже среплицировали М вместе с зашифрованными файлами. Если бы поддерживался HyperVault, то мы могли бы на DR-системе хранить цепочку снепшотов луна за несколько часов (ну, например, 12) и имели бы возможность запустить на DR-площадке сервис до момента порчи файлов. Поддержка HyperVault предполагается в будущих версиях прошивки, ориентировочно — в конце 2021 года.
Говоря о процессе тестирования DR-плана, здесь тоже есть нюанс. Процесс тестирования предполагает только автоматический запуск VМ на DR-площадке, но при этом у нас нет возможности проверить что-либо внутри VМ (запустился ли критичный для нас сервис, консистентность данных внутри и т.д.).
Я обнаружил, что интерфейс BCManager корректно работает только в FireFox — в свежих версиях Chrome не работают некоторые кнопки (например, кнопка Next при создании Protected Group).
Подводя итог, могу сказать, что продукт однозначно нужный, но пока ещё есть, что улучшать, чтобы снизить RTO, т.к. показатель RPO при репликации на уровне СХД и так может быть достаточно низкий. Буду внимательно следить за развитием продукта, а также надеяться на появление поддержки HyperVault в системах Dorado V6.
Как защищаться
Достаточно просто. Во-первых, надо выключить сервис SNMP.
Если этот протокол все же необходим, то использовать SNMPv3. Если и это невозможно, избегайте использования стандартных community string — public и private.
Настройка интерфейсов коммутатора
1) Войти в режим конфигурирования интерфейса:
[R1] interface Vlanif 1
2) Назначить IP-адрес хxх.хxх.хxх.хxх интерфейсу:
[R1-Vlanif1] ip address xxx.xxx.xxx.xxx yy
где хxх.хxх.хxх.хxх – ip адрес, yy – префикс маски подсети.
3) Выйти из режима конфигурирования интерфейса:
[SW1-Vlanif1] quit
4) Назначить шлюз по умолчанию:
[Huawei] ip route-static zzz.zzz.zzz.zzz
где zzz.zzz.zzz.zzz – ip адрес шлюза
5) Выйти из конфигурационного режима:
[SW1] quit
6) Сохранить текущую конфигурацию:
[SW1] save
Настройка транкового порта (trunk port) коммутатора
«Trunk port» или «Магистральный порт» — это канал типа «точка-точка» между коммутатором и другим сетевым устройством. Магистральные подключения служат для передачи трафика нескольких VLAN через один канал и обеспечивают им доступ ко всей сети. Магистральные порты необходимы для передачи трафика нескольких VLAN между устройствами при соединении двух коммутаторов, коммутатора и маршрутизатора.
Войти в режим конфигурирования интерфейса:
[SW1] interface Ethernet0/0/0
1) Перевести порт в состояние trunk:
[SW1-Ethernet0/0/0] port link-type trunk
2) Выйти из режима конфигурирования интерфейса:
[SW1- Ethernet0/0/0] quit
3) Сохранить текущую конфигурацию:
[SW1] save
Необходимое оборудование и программное обеспечение
Для выполнения первичной настройки сетевого активного оборудования необходимо иметь в наличии следующее оборудование и программного обеспечение:
1) ноутбук c «COM- портом» для подключения к оборудованию СПД;
Примечание: на современных персональных компьютерах и ноутбуках «COM- порт» часто отсутствует. В этом случае потребуется переходник «USB – COM (RS 232)».
2) консольные интерфейсные кабели, в зависимости от типа настраиваемого оборудования
Подготовка l2 vxlan
Сперва создадим NVE интерфейс отвечающий за инкапсуляцию/деинкапсуляцию пакетиков:
interface Nve1 #создаем NVE интерфейс source 10.1.1.1 #для m-lag пары используем anycast ip адрес mac-address 0000-5e00-0199 #обязательно для m-lag пары на обоих коммутаторах настраиваем одинаковый MAC адрес, это необходимо для работы L3 VXLANДля организации L2 VXLAN необходимо создать bridge-domain и примапить к нему vlan, l2 подинтефейс или интерфейс целиком. К одному bridge-domain могут быть примаплены разные VLANs.
bridge-domain 150 #создаем bridge-domain
vlan 150 access-port interface Eth-Trunk12 #можно мапить vlan в конфигурации bridge-domain, а можно в создавать l2 подинтерфейс vxlan vni 22150 #определяем vni evpn #создаем evpn instance route-distinguisher 10.1.1.11:22150 vpn-target 65000:22150 export-extcommunity vpn-target 65000:23500 export-extcommunity #этот rt нужен в будущем для L3 VXLAN vpn-target 65000:22150 import-extcommunity
#
interface GE1/0/9.150 mode l2 #создаем подинтерфейс encapsulation [default,dot1q,untag,qinq] #выбираем тип инкапсуляции bridge-domain 150 #мапим к нужному bridge-domain
#
interface Nve1 vni 22150 head-end peer-list protocol bgp #определяем, что для BUM трафика будет использоваться ingress replication list с автообнаружением по BGPПроделываем такую же работу на остальных коммутаторах и проверяем работу. На коммутаторах должны появиться EVPN маршруты типа 3:
Посмотрим попристальнее на анонс полученный от соседа:
BUM трафик должен ходить, можно приступать к проверке связности между хостами. Для этого с хоста VM1 пропингуем хост VM2:
ubuntu@test-vxlan-01:~$ ping 192.168.50.3
PING 192.168.50.3 (192.168.50.3) 56(84) bytes of data.
64 bytes from 192.168.50.3: icmp_seq=1 ttl=64 time=0.291 ms
--- 192.168.50.3 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.291/0.291/0.291/0.000 ms
#
ubuntu@test-vxlan-01:~$ ip neigh
192.168.50.3 dev eth0 lladdr 00:15:5d:65:87:26 REACHABLEВ это время на сети должны появиться анонсы 2 типа. Проверим:
Посмотрим анонс пристальнее:
Проверяем CAM таблицу коммутатора:
Подготовка l3 vxlan
Настало время выпустить хосты за пределы своей подсети, для этого будем использовать distributed gateway.
Для начала создадим нужный VRF:
ip vpn-instance EVPN ipv4-family route-distinguisher 10.1.1.11:23500 vpn-target 65000: 23500 export-extcommunity evpn vpn-target 65000: 23500 import-extcommunity evpn vxlan vni 23500В конфигурацию BGP Leaf коммутаторов добавляем анонс IRB:
bgp 65000
l2vpn-family evpn peer rr advertise irbСоздаем L3 интерфейс для маршрутизации в нужном VRF:
interface Vbdif150 #номер должен совпадать с номером bridge-domain ip binding vpn-instance EVPN ip address 192.168.50.254 24 mac-address 0000-5e00-0101 vxlan anycast-gateway enable arp collect host enable #генерация маршрута второго типа на основании arp записиПовторяем конфигурации на других Leaf коммутаторах и проверяем:
На некоторых моделях коммутаторов (лучше свериться с официальной документацией) необходимо создание специального сервисного интерфейса для продвижения L3 VXLAN трафика. Полоса этого интерфейса должна быть в два раза больше пиковой полосы для L3 VXLAN трафика. При наличии большого количества Vbdif интерфейсов (более 2 тысяч) требуется создание дополнительных сервисных интерфейсов.
interface Eth-TrunkXXX service type tunnel trunkport 40GE1/1/1На этом настройка L3 VXLAN завершена. Проверим доступность между хостами из разных подсетей:
ubuntu@test-vxlan-01:~$ ping 192.168.51.1
PING 192.168.51.1 (192.168.51.1) 56(84) bytes of data.
64 bytes from 192.168.51.1: icmp_seq=1 ttl=63 time=0.508 ms
--- 192.168.51.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.508/0.508/0.508/0.000 msСвязность есть, теперь проверим маршрутную информацию:
Появились маршруты второго типа включающие в себя IP адреса. Теперь проверим перетекли ли маршруты в нужный VRF:
Подготовка overlay
Для начала необходимо глобально включить поддержку EVPN на коммутаторе:
evpn-overlay enableSpine коммутаторы выполняют роль Route-reflector. Плюс нужно добавить строку undo policy vpn-target в соответствующей address family, чтобы Spine смог принять все маршруты и переслать их клиентам. Соседство строим на loopback адресах.
bgp 65000 group leafs internal peer leafs connect-interface LoopBack0 peer 10.1.1.11 as-number 65000 peer 10.1.1.11 group leafs peer 10.1.1.12 as-number 65000 peer 10.1.1.12 group leafs peer 10.1.1.2 as-number 65000 peer 10.1.1.2 group leafs peer 10.1.1.3 as-number 65000 peer 10.1.1.3 group leafs # ipv4-family unicast undo peer leafs enable undo peer 10.1.1.11 enable undo peer 10.1.1.12 enable undo peer 10.1.1.2 enable undo peer 10.1.1.3 enable # l2vpn-family evpn undo policy vpn-target peer leafs enable peer leafs reflect-client peer 10.1.1.11 enable peer 10.1.1.11 group leafs peer 10.1.1.12 enable peer 10.1.1.12 group leafs peer 10.1.1.2 enable peer 10.1.1.2 group leafs peer 10.1.1.3 enable peer 10.1.1.3 group leafsНа Leaf коммутаторах настраиваем нужный address family. Для m-lag пары хочется сделать политику подменяющую next-hop на anycast loopback ip адрес, но без такой политики все работает. Huawei подменяет next-hop адрес на адрес который указан в качестве source ip адреса интерфейса NVE. Но если вдруг возникнут проблемы с автоматической подменой всегда можно навесить политику руками:
bgp 65000 group rr internal peer rr connect-interface LoopBack0 peer 10.1.1.100 as-number 65000 peer 10.1.1.100 group rr peer 10.1.1.101 as-number 65000 peer 10.1.1.101 group rr # ipv4-family unicast undo peer rr enable undo peer 10.1.1.100 enable undo peer 10.1.1.101 enable # l2vpn-family evpn policy vpn-target peer rr enable peer 10.1.1.100 enable peer 10.1.1.100 group rr peer 10.1.1.101 enable peer 10.1.1.101 group rrПроверяем, что overlay control plane собрался:
Подключение ноутбука к оборудованию
Подключить рабочий ноутбук с помощью консольного интерфейсного кабеля к разъему «console» оборудования На разных типах оборудования интерфейс для подключения консольного кабеля может называться по-разному, возможные варианты – «console», «con», «monitor» и т.п.
Полупроводниковые тонкости
Важные компоненты СХД мы дублируем: если что-то выйдет из строя – всегда есть подстраховка. К примеру, модули питания у младших моделей работают по схеме 1 1, у более солидных – 2 1 и даже 3 1.
Контроллеры, которых в системе хранения как минимум два (одноконтроллерные системы мы не поставляем) тоже резервируются. В СХД 6800-й и более старших серий резервирование производится по схеме 3 1, в младших моделях – 1 1.
Зарезервирован даже модуль управления (management board), который непосредственно на работу системы не влияет, а нужен только для изменения конфигурации и мониторинга. Кроме того, любые интерфейсные платы расширения для СХД у нас продаются только парами, чтобы у клиента имелся резерв.
Все компоненты — БП, вентиляторы, контроллеры, менеджмент-модули и т.п. — оснащены микроконтроллерами, способными реагировать на определенные ситуации. Например, если вентилятор начинает сам по себе сбавлять обороты, на управляющий модуль посылается сигнал тревоги.
В результате заказчик имеет полную картину состояния СХД – и может при необходимости заменить некоторые компоненты самостоятельно, не дожидаясь прибытия нашего сервисного инженера. А если политика безопасности заказчика позволяет, мы настраиваем контроллеры так, чтобы они передавали информацию о состоянии железа в нашу техподдержку.
Сброс настроек коммутатора huawei в заводские без доступа к системе
1) Подключить рабочий ноутбук к коммутатору и запустить телекоммуникационное программное обеспечение согласно.
2) Подать питание на коммутатор. Дождавшись строки «Press Ctrl B to break auto startup» при загрузке коммутатора, нажать на клавиатуре сочетание клавиш «Ctrl B» (дается на это не более 3 секунд, после чего продолжается загрузка устройства).
Свои чипы лучше и понятнее
Мы – единственная компания, разрабатывающая собственные процессоры, чипы и контроллеры твердотельных накопителей для своих СХД.
Так, в некоторых моделях в качестве основного процессора системы хранения (Storage Controller Chip) мы используем не классический Intel x86, а ARM-процессор HiSilicon, нашего дочернего предприятия. Дело в том, что ARM-архитектура в СХД – для расчета тех же RAID и дедупликации – показывает себя лучше, чем стандартная х86-я.
Наша особая гордость — чипы для SSD-контроллеров. И если серверы у нас могут комплектоваться полупроводниковыми накопителями сторонних производителей (Intel, Samsung, Toshiba и др.), то в системы хранения данных мы устанавливаем только SSD собственной разработки.
Микроконтроллер модуля ввода-вывода (smart I/O чип) в системах хранения – тоже разработка HiSilicon, как и Smart Management Chip для удаленного управления хранилищами. Использование собственных микросхем помогает нам лучше понимать, что происходит в каждый момент времени с каждой ячейкой памяти. Именно это позволило нам свести к минимуму задержки при обращении к данным в тех же СХД Dorado.
Для магнитных дисков с точки зрения надежности чрезвычайно важен постоянный мониторинг. В наших СХД поддерживается система DHA (Disk Health Analyzer): диск сам непрерывно фиксирует, что с ним происходит, насколько хорошо он себя чувствует. Благодаря накоплению статистики и построению умных предиктивных моделей удается предсказать переход накопителя в критическое состояние за 2-3 месяца, а не за 5-10 дней.
Технологии
Тут описаны технологии, которые не рассмотрены в RAID-контроллерах
Cache mirroring
Cache mirroring используется при наличии нескольких контроллеров в СХД (у Huawei всегда несколько контроллеров, минимум 2). Данные между контроллерами по шине синхронизации синхронизируются для целостности данных в случае отказа одного из контроллеров. Cache mirroring делается всех типов операций – read/write/mirror. Причем главным считается write.
Multipathing
Multipathing – поддержка нескольких аплинк каналов от СХД до серверов. Нет зависимости от канала/промежуточного коммутатора. Особенность технологии еще и в том , что можно сделать так, чтобы для сервера оба канала виделись как один ЖД (LUN), а не по одному LUN на каждый канал.
Data coffer
На случай полного фатала с питанием (выход из строя двух БП/обоих лучей питания) в controller enclosure встроен функционал сохранения данных RAID кэша. Реализуется не через BBU ОЗУ или суперконденсаторы flash, как на RAID-контроллерах серверов (и на старших моделях СХД), а используя батареи (батарейные блоки BBU) служебное пространство 4 дисков.
При проблеме с питанием данные из кеша контроллера переносятся на специальные разделы coffer disk’ов (раздел равен кешу контроллера, 4 диска – 2х2 диска в RAID1). Остальная часть дисков, не отведенная под раздел coffer, используется стандартно. После включения контроллер выгружает данные из coffer куда нужно.
LUN copy
Копирование LUN. Требует запрет на запись (не на чтение) в данный LUN для корректного снятия копии в определенный момент времени.
HyperClone (LUN clone) и Synchronization
Мгновенное копирование LUN используя синхронизацию (synchronization) между LUN. Не требует запрета на чтение, но занимает весь объем, отведенный под LUN, а не только объем данных LUN.
Синхронизация может происходить как между основным и резервным LUN, так и обратно. Для восстановление данных используется обратная синхронизация с клонированного LUN на основной (reverse synchronization). После синхронизации происходит обрыв синхронизации (split)
HyperSnap (Snapshot)
Позволяет снять копию системы (определенного LUN) в определенный момент времени. Есть у всех вендоров СХД. У Huawei основан на технологии copy-on-write (еще популярен у вендоров allocated-on-write).
- Для снятия snapshot не требуется остановка системы, в отличии от LUN copy.
- Snapshot занимает только пространство отведенное под ненулевые данные LUN, а не весь объем, отведенный под LUN, как это делает Clone.
В СХД типа OceanStor 9000 snapshot может быть сделан за одну секунду без влияния на сервис. Подробнее зачем нужны snapshot/replication см. в статье backup.
Существует два варианта восстановления из snapshot:
- side-by-side recovery: создается сопоставление snapshot LUN для хоста, который “видит” оригинальный LUN. В результате конкретные данные могут быть скопированы на уровне ОС.
- rollback function: оригинальный LUN (и все его данные) просто подменяется snapshot LUN.
HyperReplication (Remote Replication)
Репликация данных с одного СХД на другой. Требует несколько одновременно работающих СХД в отличии от LUN copy/snapshot, которые могут быть сохранены на том же СХД. Репликация может быть синхронная или асинхронная (с задержкой), в зависимости от ширины канала и задержки:
- Синхронная репликация – при записи хоста на основной СХД хост не получит подтверждение успешности записи пока основной СХД не получит подтверждение от СХД, с которым происходит репликация.
- Асинхронная репликация – основной СХД сразу отвечает хосту, а уже на фоне просто делается snapshot и далее данные передаются на второй СХД.
В настройках обычно можно задавать максимальную полосу канала, выделяемую под репликацию. Кроме того реплики могут быть полными или инкрементальными.
Могут быть разные варианты реализации репликации между СХД: один к одному/ко многим или двухсторонние реплики. Подробнее зачем нужны snapshot/replication см. в статье backup.
Квоты
Квоты позволяют сделать ограничение для определенных пользователей по объему выделяемого им пространства. Зачастую поддерживается интеграция с NIS/LDAP/AD (слайд для СХД OceanStor 9000).
WORM
WORM – write once read many. Система блокирует после создания файла его изменение и удаление. Таким образом обеспечивается неизменяемость информации (отчеты сотрудников, правовая или медицинская информация). Через определенный период, заданный админом, файл можно удалить или повторно заблокировать, но изменить нельзя.
QoS
Аналогия QoS в IP-сетях, вместо пакетов используются I/O requests. Можно в системе настраивать приоритетность обработки тех или иных запросов на чтение/запись на определенный LUN. В зависимости от приоритета формируются очереди.
Дедупликация
В СХД может быть реализован функционал глобальной дедупликации данных (защиты от дублирования) путем сравнения файлов или объектов между собой (OceanStor 9000). Подробнее о дедупликации см. в отдельной статье.
HyperThin/SmartThin
Thin LUN – динамический LUN, который автоматически расширяется при заполнении. ОС видит такой LUN как обычный Thick LUN, но по факту контроллер предоставляет меньше объема, чем размер LUN и автоматически расширяет его при потребности ОС.
Пространство без данных можно использовать для другого LUN. В результате пространство используется эффективнее, но в случае полной забивки динамического LUN может произойти коллапс. При создании Thin LUN отжирает 64МБ под свои задачи и по мере появления данных в Thin LUN потребует еще служебного пространства, помимо основных данных.
SmartTier
У вендоров может быть реализована поддержка разных типов дисков (SSD, SAS, NL-SAS). В результате разные по типу диски могут стоять в одной полке. В случае Huawei технология называется SmartTier и поддерживается на RAID 2.0 и СХД OceanStor 9000 (тут она InfoTier). Для работы SmarTier на Disk Domain нужно чтобы в нем были диски разных типов (не обязательно три типа, можно и два).
SmartTier на основе технологии dynamic storage tiering (DST) определяет, какие данные более востребованы и переносит их на SSD (high-perfomance tier), менее же востребованные же переносит на HDD (perfomance tier: SAS, capacity tier: NL-SAS). Происходит это в три этапа:
- Анализ входящих/исходящих операций (i/o monitoring)
- Анализ возможностей размещения данных (data placement analysis)
- Перемещение данных (data relocation)
Перемещение происходит в ненагружанные часы (можно задать вручную или использовать автоматический выбор на основе i/o), потому что потребляет ресурсы СХД . Определенные файлы можно закрепить за каким то уровнем. По умолчанию функционал выключен, даже если лицензия куплена – нужно задавать настройки политик перемещения для определенного LUN (automatic, highest, lowest, no relocation).
Специфические утилиты восстановления
Могут быть реализованы специфические утилиты восстановления данных, например, функционал по восстановлению видео (в OceanStor 9000). Как говорит автор до такого лучше не доводить – лучше следить за состоянием RAID/ЖД в нем, делать snapshot и прочее.
Шесть девяток
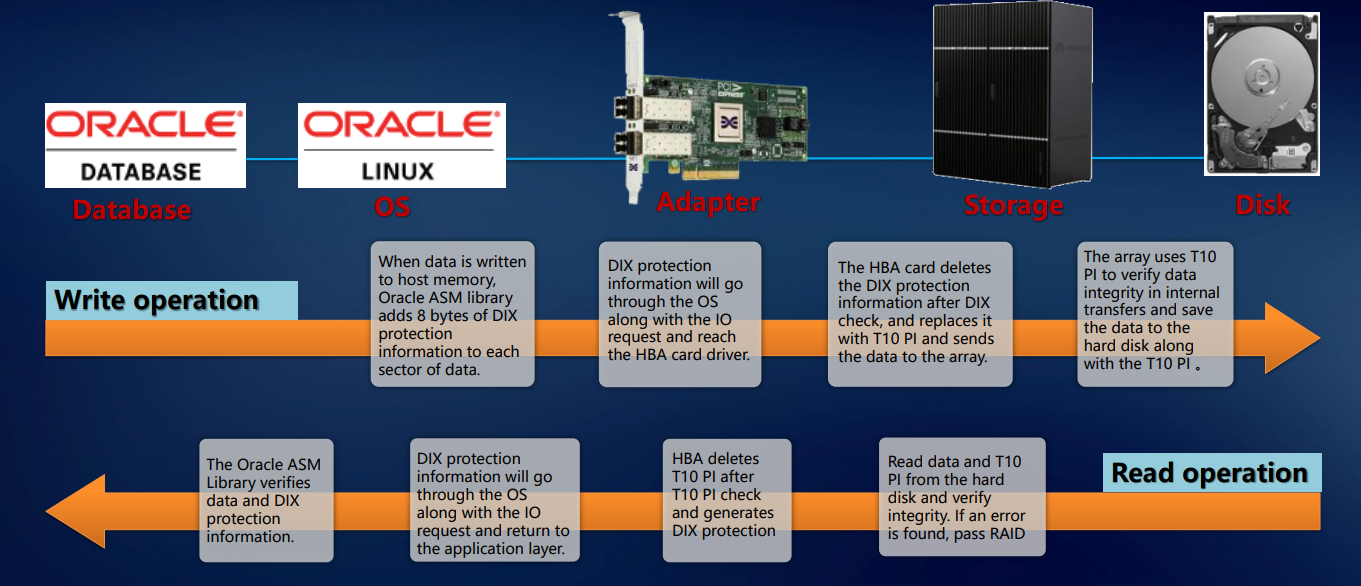
Перечисленное выше позволяет говорить об отказоустойчивости наших систем на уровне всего решения. Проверка реализуется на уровне приложения (например, СУБД Oracle), операционной системы, адаптера, СХД – и так вплоть до диска. Такой подход гарантирует, что ровно тот блок данных, который пришел на внешние порты, безо всяких повреждений и потерь будет записан на внутренние диски системы. Это подразумевает enterprise-уровень.
Для надежного хранения данных, их защиты и восстановления, а также быстрого доступа к ним мы разработали целый ряд фирменных технологий.
HyperMetro – наверное, самая интересная разработка последних полутора лет. Готовое решение на базе наших систем хранения для построения отказоустойчивого метро-кластера внедряется на уровне контроллера, никаких дополнительных шлюзов или серверов, кроме арбитра, оно не требует. Реализуется просто лицензией: две CХД Huawei плюс лицензия – и это работает.
Технология HyperSnap обеспечивает непрерывную защиту данных без потери производительности. Система поддерживает RoW. Для предотвращения потери данных на СХД в каждый конкретный момент используется множество технологий: различные снэпшоты, клоны, копии.
На основе наших СХД разработано и проверено на практике как минимум четыре решения для аварийного восстановления данных.
Еще у нас есть решение для трех дата-центров 3DC Ring DR Solution: два ЦОДа в кластере, на третий идет репликация. Можем организовать организована асинхронную репликацию или миграцию со сторонних массивов. Имеется лицензия smart virtualization, благодаря чему можно использовать тома с большинства стандартных массивов с доступом по FC:
В итоге на уровне всего решения можно получить надежность шесть девяток, а на уровне локальной СХД — пять девяток. В общем, мы старались.
Заключение
В данной статье я попытался описать процесс настройки EVPN VXLAN фабрики на базе оборудования Huawei и привести некоторые команды необходимые в процессе отладки.
Спасибо за внимание!